Window functions have been a very requested feature for ClickHouse for years. They exist in other databases like Postgres and let you perform calculations across a set of table rows that are somehow related to the current row. They behave similar to regular aggregate functions but, with window functions, rows don’t get grouped into a single output row.
That enables you to write simpler queries and to do certain things with window functions that you couldn’t do otherwise. Also, you can use the same syntax that you’re already used to from other databases like Postgres or MySQL.
Lots of work has gone into adding window functions to ClickHouse in the last few months, and they’re now available as an experimental feature (docs).
In this post we’ll explore a bit what you can do with them.
Window functions
Let’s load some data first. We’ll use a sample of the events dataset we used for our getting started guides. Download it from here or running curl https://storage.googleapis.com/tinybird-assets/datasets/guides/events_10K.csv -o events_10K.csv.
Then create a table to store it like this:
And load the data onto the table you’ve just create doing ch client -q 'insert into events format CSV' < events_10K.csv.
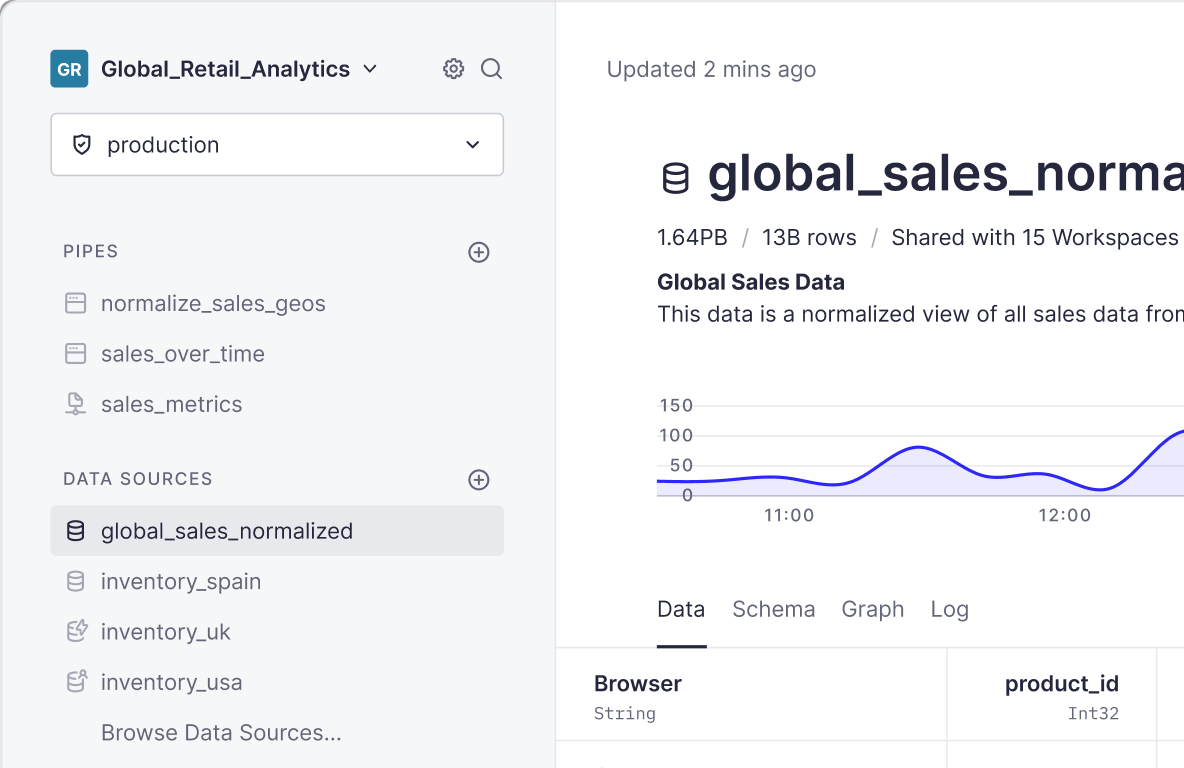
This is what a sample of the data looks like
Now we’re ready to make some queries. These are some of the things that window functions enable you to do.
Note: This is an experimental feature. To be able to use it, you’ll have to run the following command in your ClickHouse client console before you use any window function:
Now we’re ready to go.
Cumulative sums, averages and other aggregate functions
Until now, the only way to do cumulative sums and averages was using groupArray, arrayJoin, groupArrayMovingSum and groupArrayMovingAvg functions, like described here.
For example, this is how you’d go about getting the daily and cumulative count of how many buy events happened since we started recording data, and the daily and cumulative revenue as well.
WINDOW clause
In the previous query we repeated twice the over (order by date asc rows unbounded preceding) expression. That’s error prone, and to avoid that we can define the window just once and reuse it as many times as we want in our query.
The syntax is the same as for Postgres (docs)
The previous query would be rewritten like this, using the window clause:
Moving counts and averages
If we wanted to calculate rolling aggregate functions for only the last (or next) N rows, that’s also possible. For example, this is how you’d calculate the 30-day moving average of revenue, and the sum of revenue for the past 30 days.
PARTITION BY clause
The PARTITION BY clause divides rows into multiple groups or partitions to which the window function is applied. So if you wanted to calculate the cumulative revenue per month, since the beginning of each year, you’d do it like this:
RANGE clause
It’s possible to define the window boundaries by a given value difference, instead of rows. If the column used for the window is a DateTime column, the value will be measured in seconds. This is how you’d calculate the total number of purchases and the revenue for the past hour, for every buy event:
RANK, ROW_NUMBER and DENSE_RANK
These functions are also supported, and they behave the same way as in Postgres. This is how you’d be the top purchases of each day, ranked by the money spent:
As of the time of writing this, there seems to be some issues related to sorting when a window with a partition by expression is used. Update (2021-03-22): this is now fixed.
As a side note, a similar result could be obtained with the LIMIT BY clause.
What else?
There are many other promising features coming up. On the ClickHouse GitHub repository, there is a ticket with all the features that are in the roadmap for 2021 and their current status. Here are some additional ones we’re quite excited about:
Nested and semistructured data
Right now, ClickHouse already has a Nested data type that lets you have columns that store more than one field inside, with a single nesting level.
There’s work being done to allow an arbitrary nesting level. They’d eliminate the need to save JSON columns as strings, allow different column representations to store the same DataType, dynamic columns and much more
Separation of storage and compute
To allow, for example, to store replicas of the data on S3. Follow the progress on this PR
A PostgreSQL table engine
An experimental MySQL table engine already exists, that lets you run queries over data stored originally on a MySQL database. A PostgreSQL engine is also in the works
Projections
Projections will let you do some simple aggregations with the performance of a Materialized View, but without having to create a MV. They’ll be defined at the table level. Read a much more detailed explanation with examples in this issue
Backups
Having the possibility to import and export data and metadata to S3, a local filesystem or another ClickHouse server. Allowing incremental backups, and much more. See all the details in this ticket
One more thing
Tinybird lets you define dynamic endpoints to do real-time analytics at scale on top of ClickHouse. If you’d like to use our product, sign up here