Amazon S3 isn't just the most widely adopted object storage solution in the world; it's the most widely adopted data storage solution in the world, period. As of its 15th anniversary in 2021, Amazon S3 held 100 trillion objects and counting.
Last year, we introduced the S3 Connector, a fully managed data ingestion connector that makes it fast and simple to build real-time analytics APIs over files in Amazon S3.
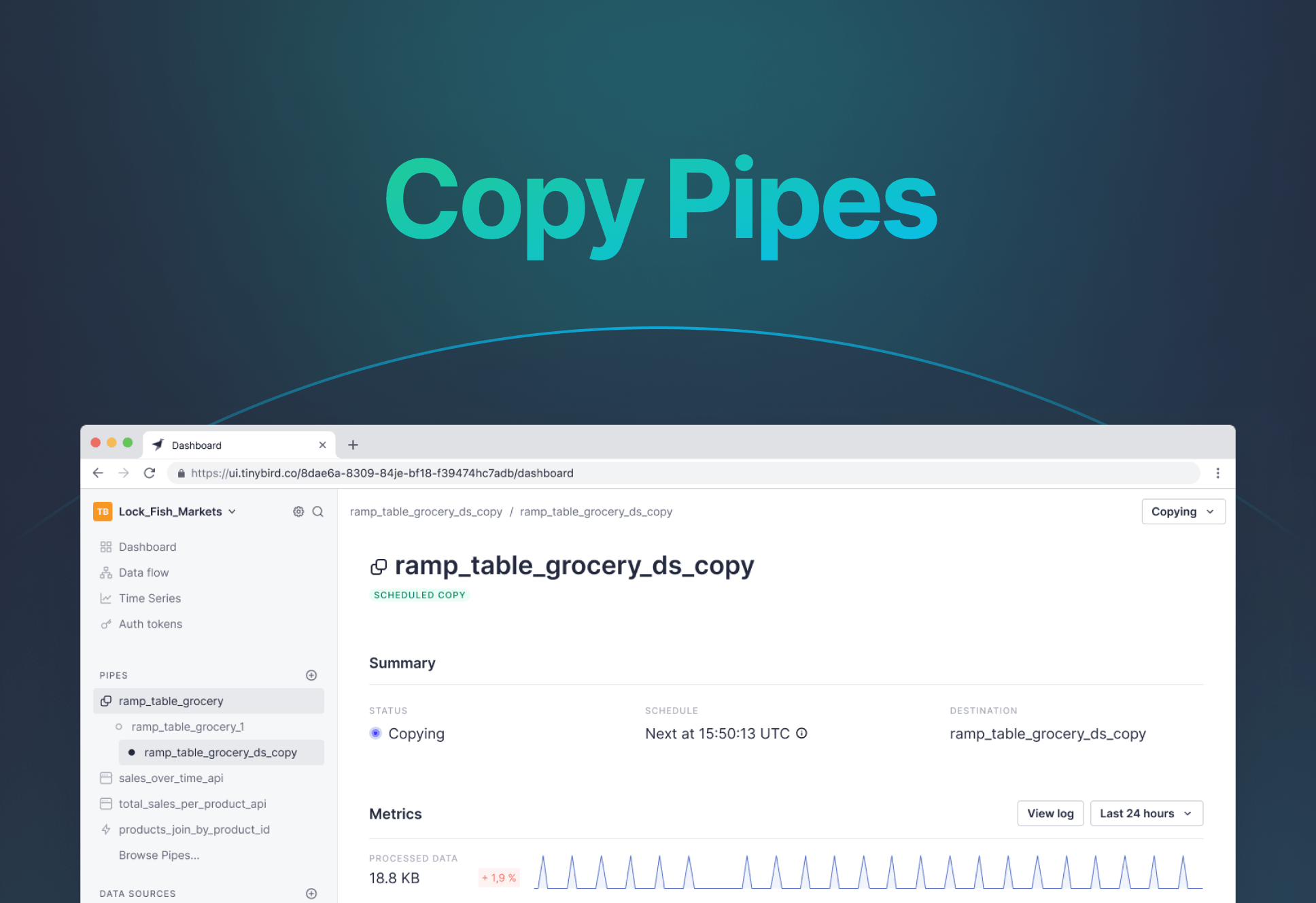
Today, we flip the script, making it fast and simple to put your analytical data products back into object storage with the S3 Sink.
Why put data back in Amazon S3?
Many Data Engineering Teams use Tinybird as the Source of Truth for building user-facing data products. The data in Tinybird is the data their customers see and use.
Understandably, Data Engineers want all of their systems to work from the source of truth to ensure consistency across their user-facing dashboards, machine learning models, internal reports, and any other data applications that rely on the same data sets.
Before today, if you wanted to export data from Tinybird into an external data system, you'd have to build an external ETL.
Amazon S3 is a "common ground" for data people. It's a highly scalable and exceptionally cost-efficient long-term storage solution that works well as an intermediary between different data systems. The world of Amazon S3 integrations is vast, extending well beyond the AWS cloud ecosystem. Since we want Data Engineers to easily get data out of Tinybird and into external systems, Amazon S3 was the logical place to start.
Before today, if you wanted to export data from Tinybird to Amazon S3, you'd have to build an external ETL, which added additional cost and complexity to set up and maintain.
With the S3 Sink, Data Engineers have a fully integrated experience consistent with the well-loved Tinybird development workflow. You can now build real-time APIs and hydrate your data lake from a single source of truth.
The S3 Sink has been extensively tested in production by Tinybird customers during the private beta, and some of their use cases for the S3 Sink include:
- Building a SaaS or data platform on top of Tinybird and regularly sending data exports to their clients or partners.
- Regularly exporting Source of Truth data products from Tinybird to Amazon S3 to load it into data warehouses like Snowflake for running machine learning models or building internal reports.
- Sharing the data they have in Tinybird with other systems in their organization, in bulk.
“Tinybird is the Source of Truth for our analytics; the data in Tinybird is the data our customers see in their user-facing dashboards. Now, instead of using an external ETL to get that SOT data out of Tinybird, we're using the S3 Sink, and it’s really simplified the entire process.”
Staff Data Engineer
How to export data from Tinybird to Amazon S3
As with most things in Tinybird, exporting to Amazon S3 from Tinybird is very intuitive. A condensed version of the process is shown below. For more thorough steps, including details on billing, observability, and limits, check out the S3 Sink documentation or watch the screencast at the top of this post.
Step 1: Create a Sink Pipe
Create a Pipe as you always do in Tinybird. This time, however, instead of publishing it as an Endpoint, you create a Sink.
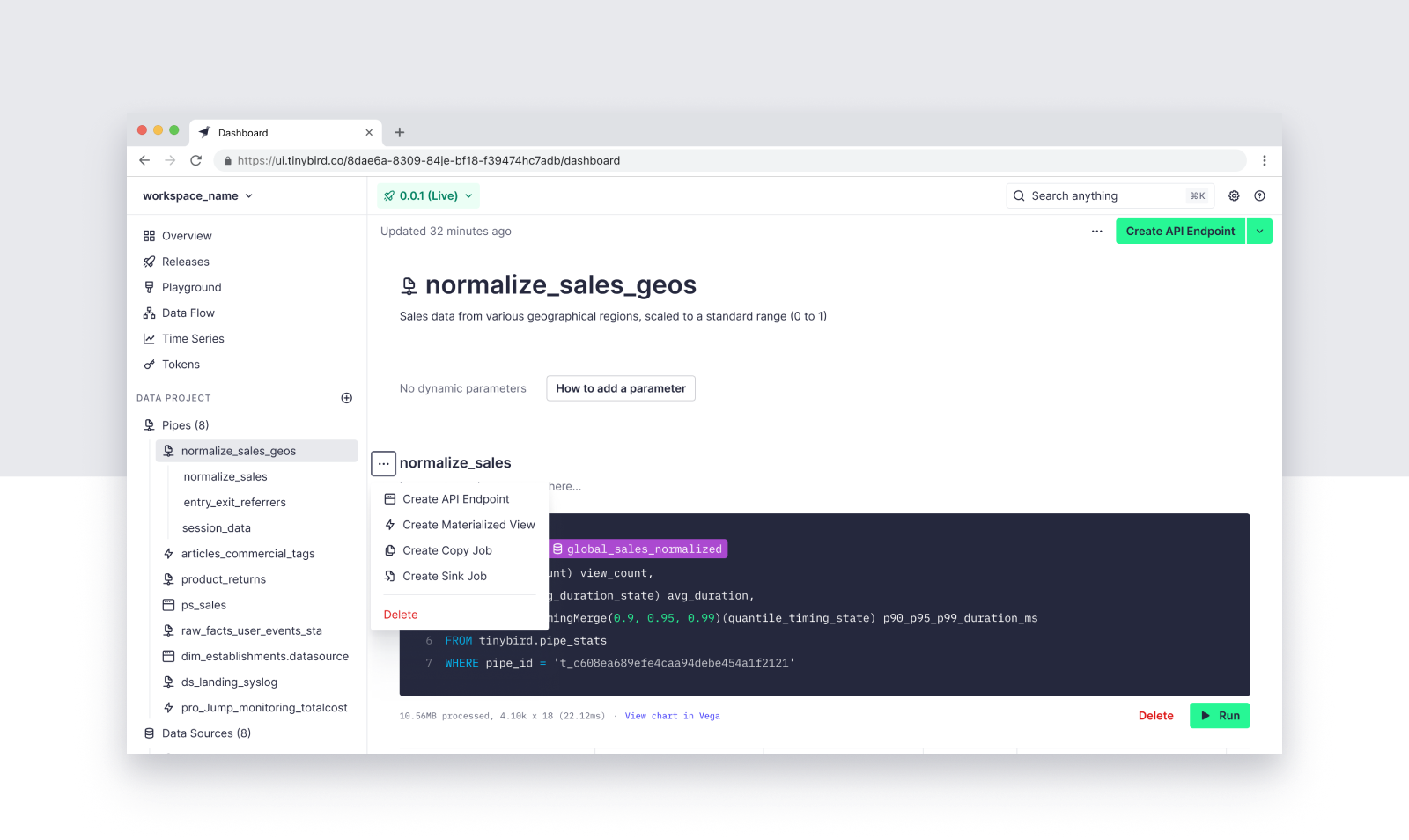
Step 2: Select Amazon S3 as your Sink
Amazon S3 is the only Tinybird Sink currently supported, but new Sinks are on the way! For now, select Amazon S3 as your Sink destination.
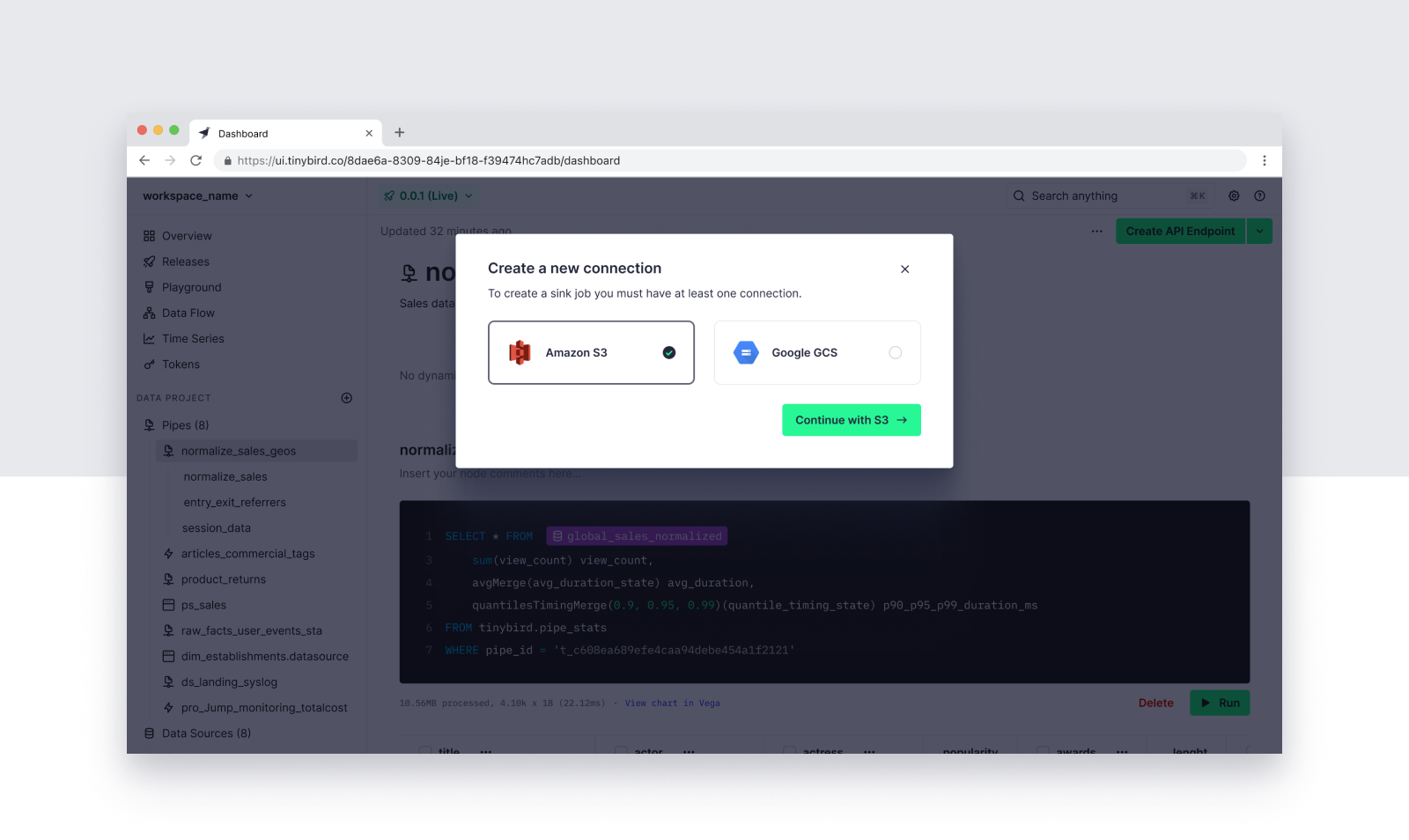
Step 3: Allow Tinybird to access S3
Create an IAM Policy in your Amazon Web Services console to allow Tinybird to access your S3 Bucket. Tinybird supplies the exact JSON snippet you'll need to create the Policy, so just copy that snippet, paste it into AWS, and save.
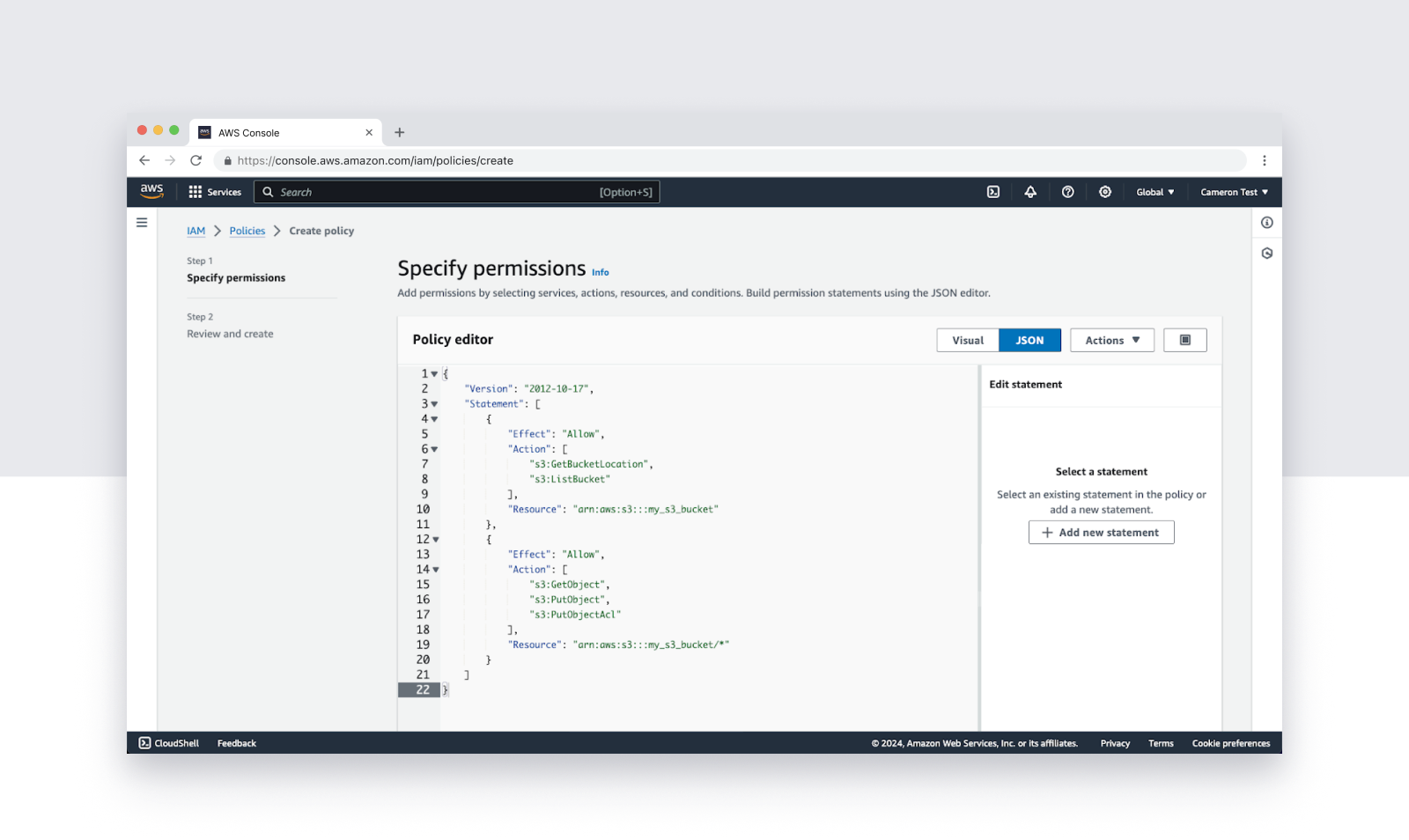
Then create an IAM Role in AWS and attach the Policy you just created. Again, Tinybird provides the snippet, so it's just a copy and paste.
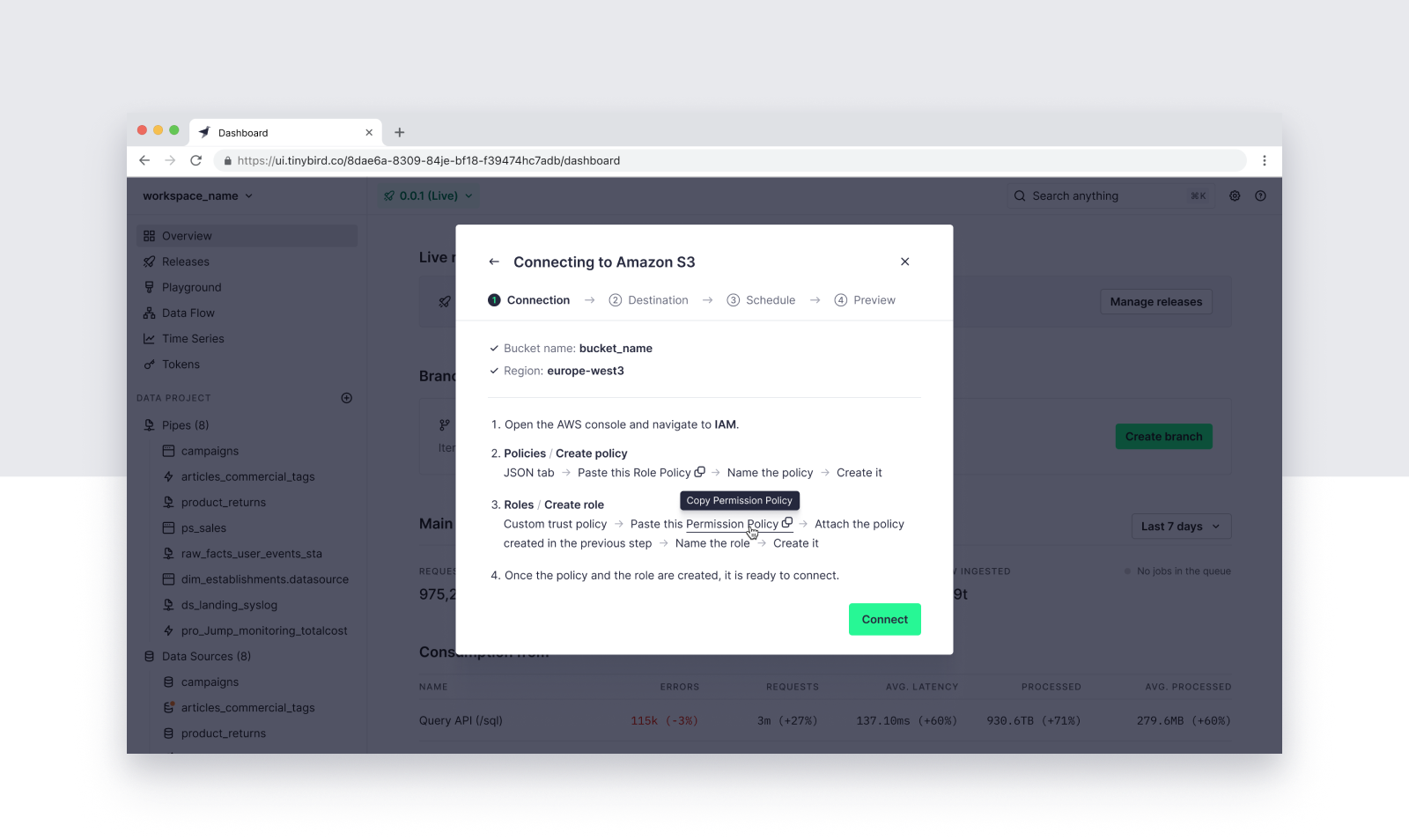
Step 4: Connect Tinybird to S3
Once you've secured the connection between Tinybird and Amazon S3, you can name your connection and start defining your Sink Job.
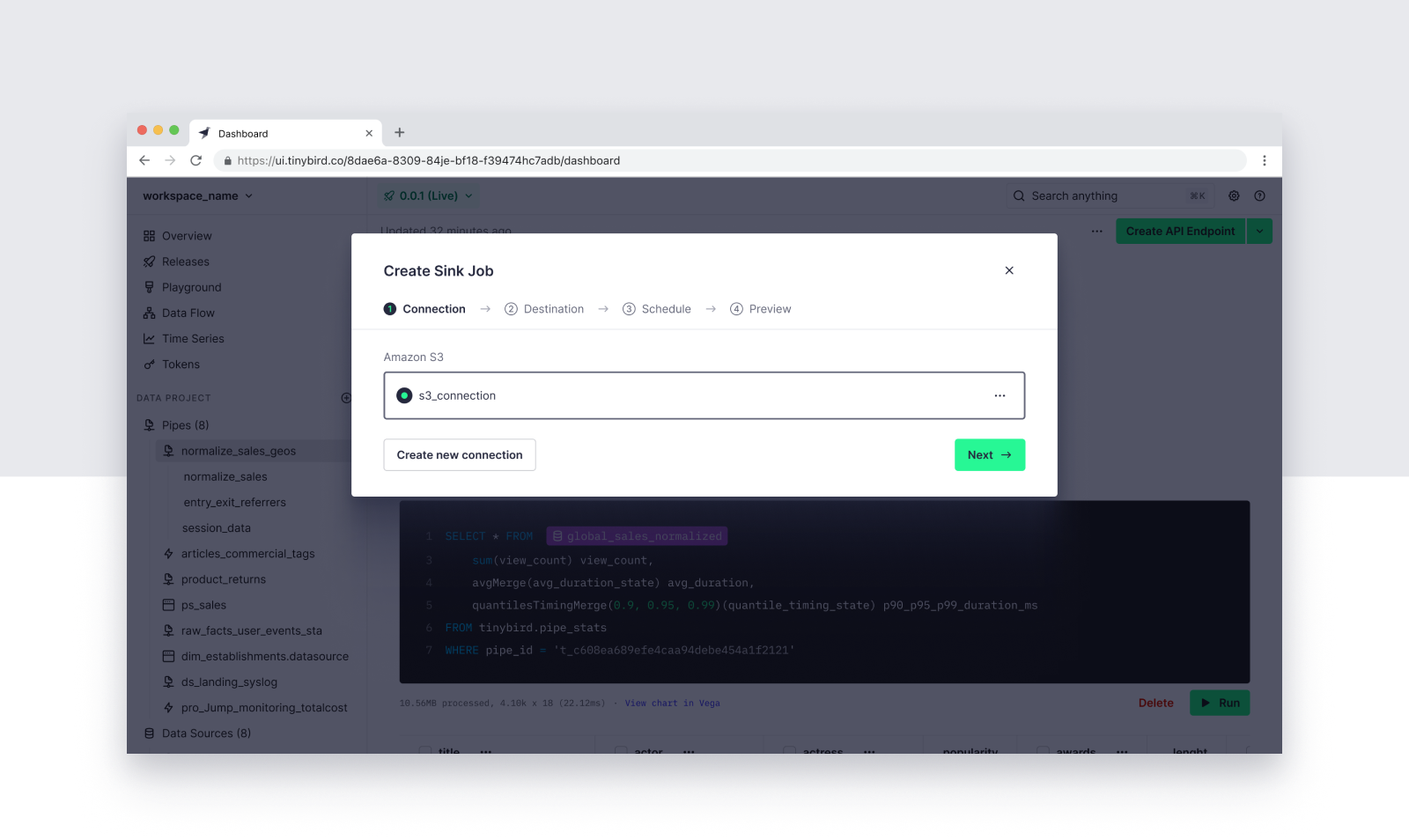
Step 5: Define the Sink Job
Define the schedule and file template for your Sink Job. You can use dynamic parameters in your filename template to create multiple files based on the results of your Pipe, select multiple file types, and choose a compression codec.
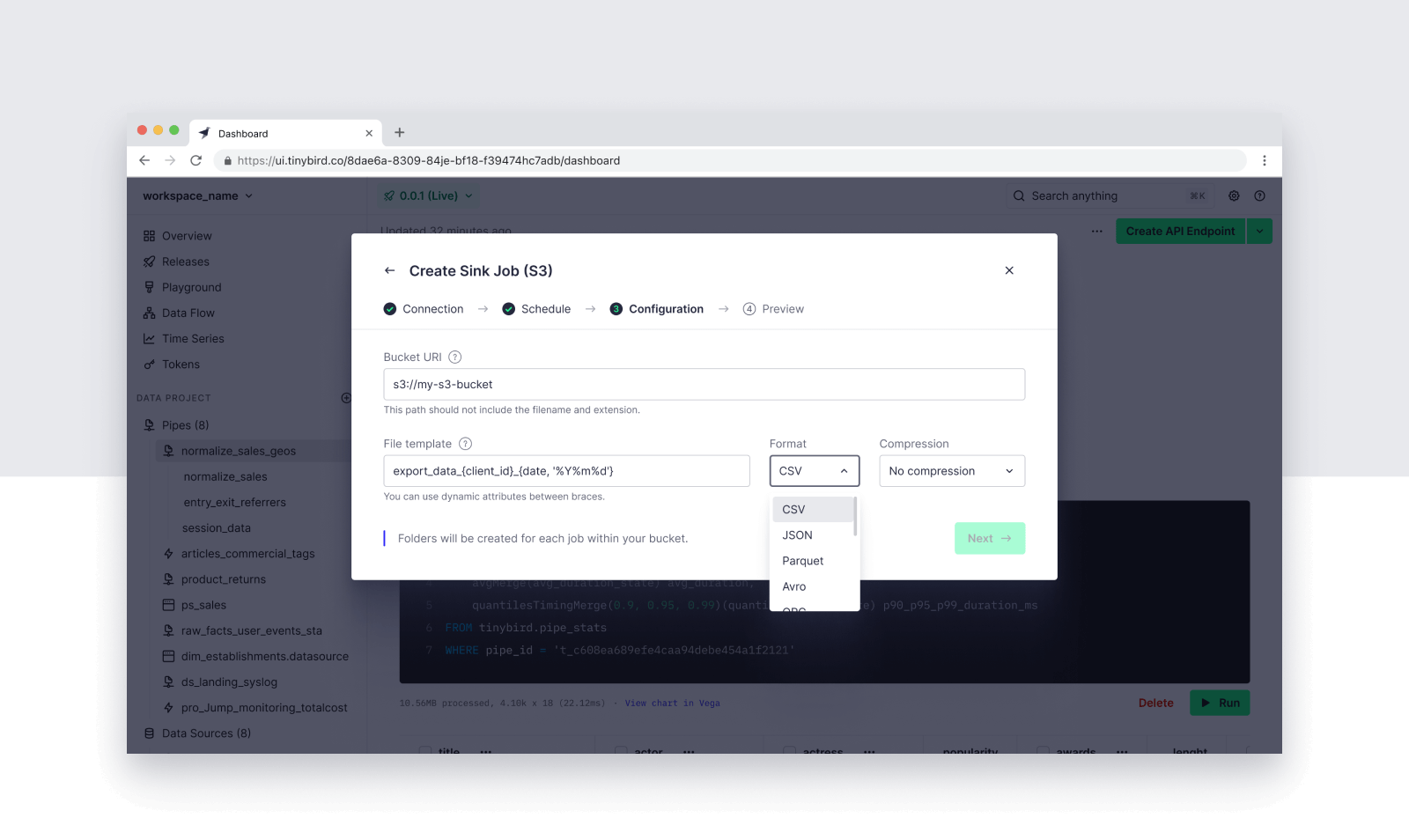
client_id and date in the result set.Step 6: Trigger the S3 Sink Job
Once the Sink Job is created, you can monitor the job process, pause the Sink schedule, or trigger an On Demand Sink Job from the Sink UI.
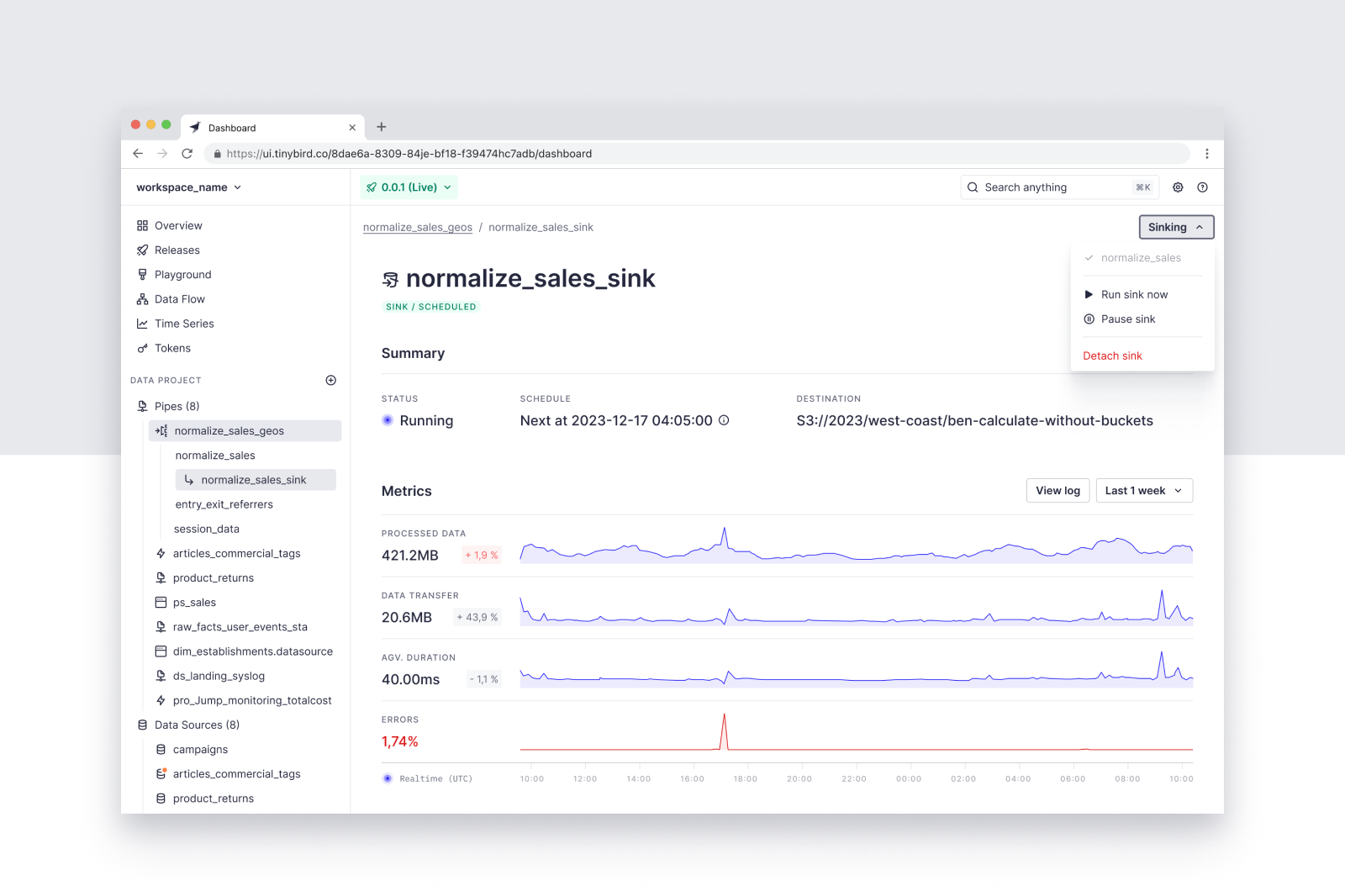
Getting started with the S3 Sink
The S3 Sink is now available for all Tinybird users on Pro or Enterprise plans. If you're on a free Build plan and want access to the S3 Sink, you will need to upgrade your Workspace to a Pro or Enterprise plan.
To learn more about the S3 Sink, please refer to the documentation or watch the screencast above.
If you'd like more guidance on how and when to use the S3 Sink, including information on observability, pricing, and optimizations, sign up for our upcoming free virtual training on Thursday, April 18th. You’ll learn how to build an end-to-end pipeline with the S3 Sink, and we’ll answer any questions you have.

If you're already using the S3 Sink or have ideas on how we can continue to expand our ecosystem of connectors, we'd love to hear from you. Please email us at hi@tinybird.co or join our public Slack community to provide feedback.
Not using Tinybird?
If you're new to Tinybird, you can sign up for a free account and start building. The Build plan is free, with no time limit or credit card required, and you'll be building end-to-end real-time data pipelines in minutes. If you have questions as you work, you can join our public Slack community and ask away.