We’ve been working hard lately to make some big improvements on the product lately. Keep reading to learn more about them!
Big Query connector
From now on, it’s possible to ingest data to Tinybird directly from Google Big Query using our CLI. Read more about this in our docs.
CLI improvements
Our CLI tool received lots of enhacements this past two weeks. Some of the biggest ones:
- Added support for truncate operations: tb datasource truncate <datasource_name>
- Added support for replace operations: tb datasource replace <datasource_name> <URL or file>
- Added support for replace with condition operations: tb datasource replace <datasource_name> <URL or file> –sql-condition=”country=’ES’”
- Added support for ENGINE_SETTINGS and ENGINE_TTL
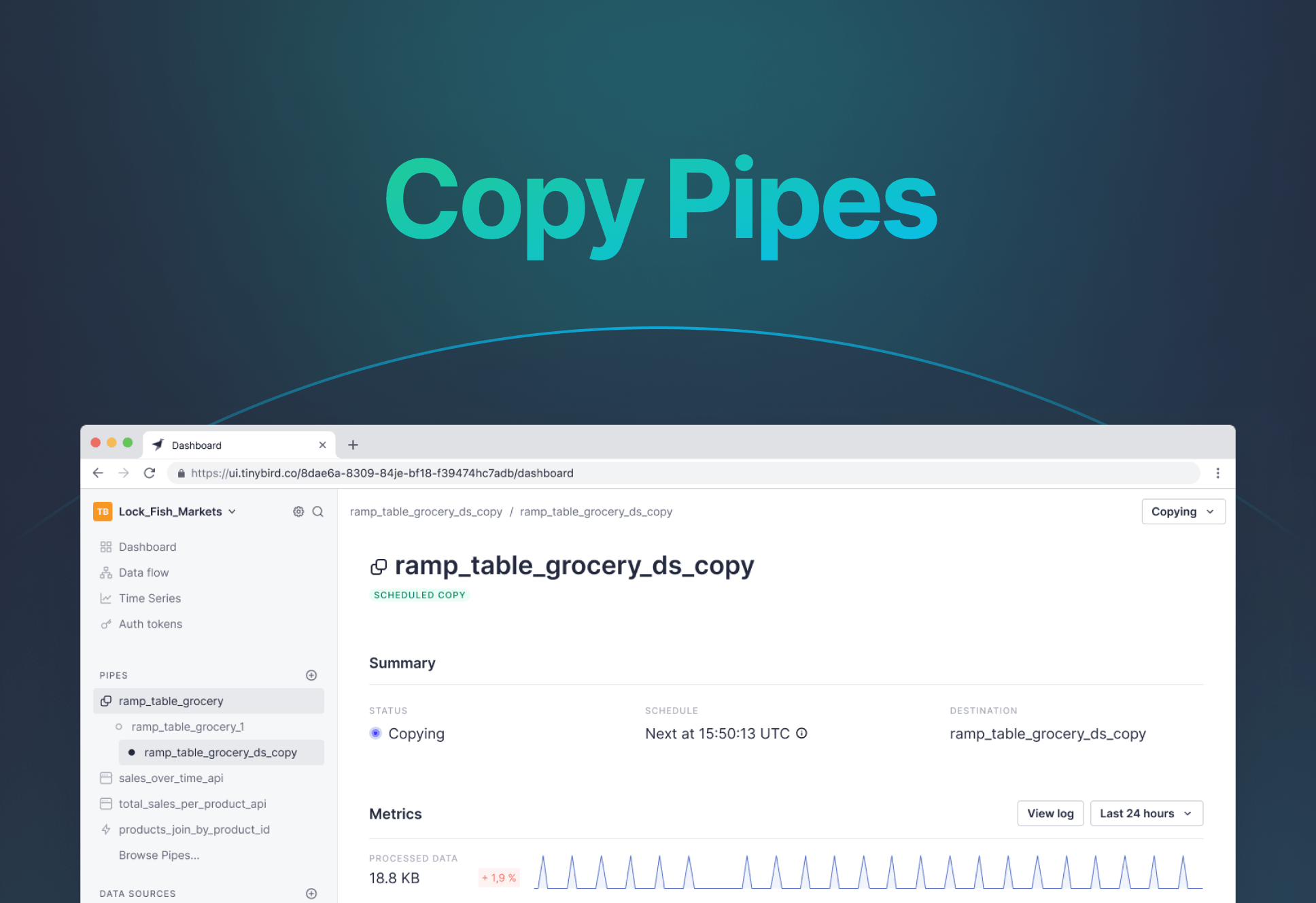
- Added a progress bar when waiting for a populate job to finish. Add the --wait flag when doing tb push to see it.
- Added population time to populate pipe option. It returns the actual population time from the population job when debug is used along with populate and wait options. Add the --debug flag when doing tb push to see it.
- Display a warning if there is a more recent version
- Added CLI workspace commands. Now you can also switch workspaces from the CLI
Check them all and the rest here
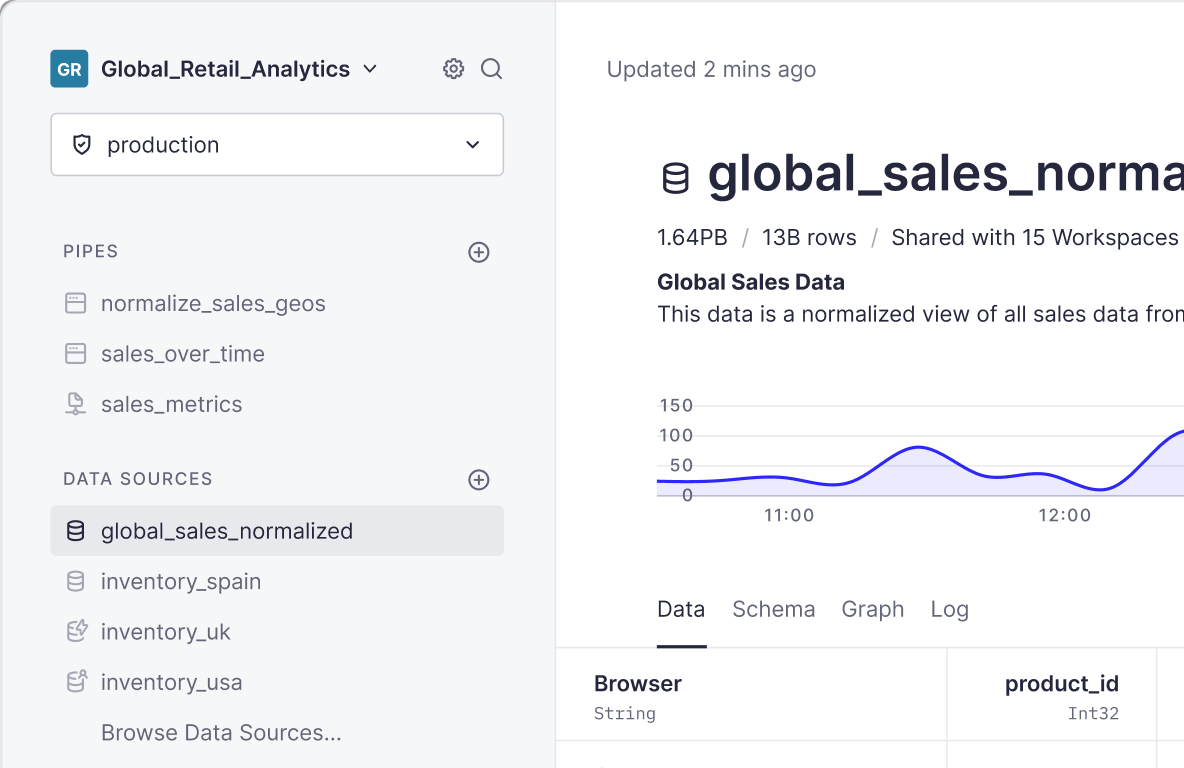
UI Improvements
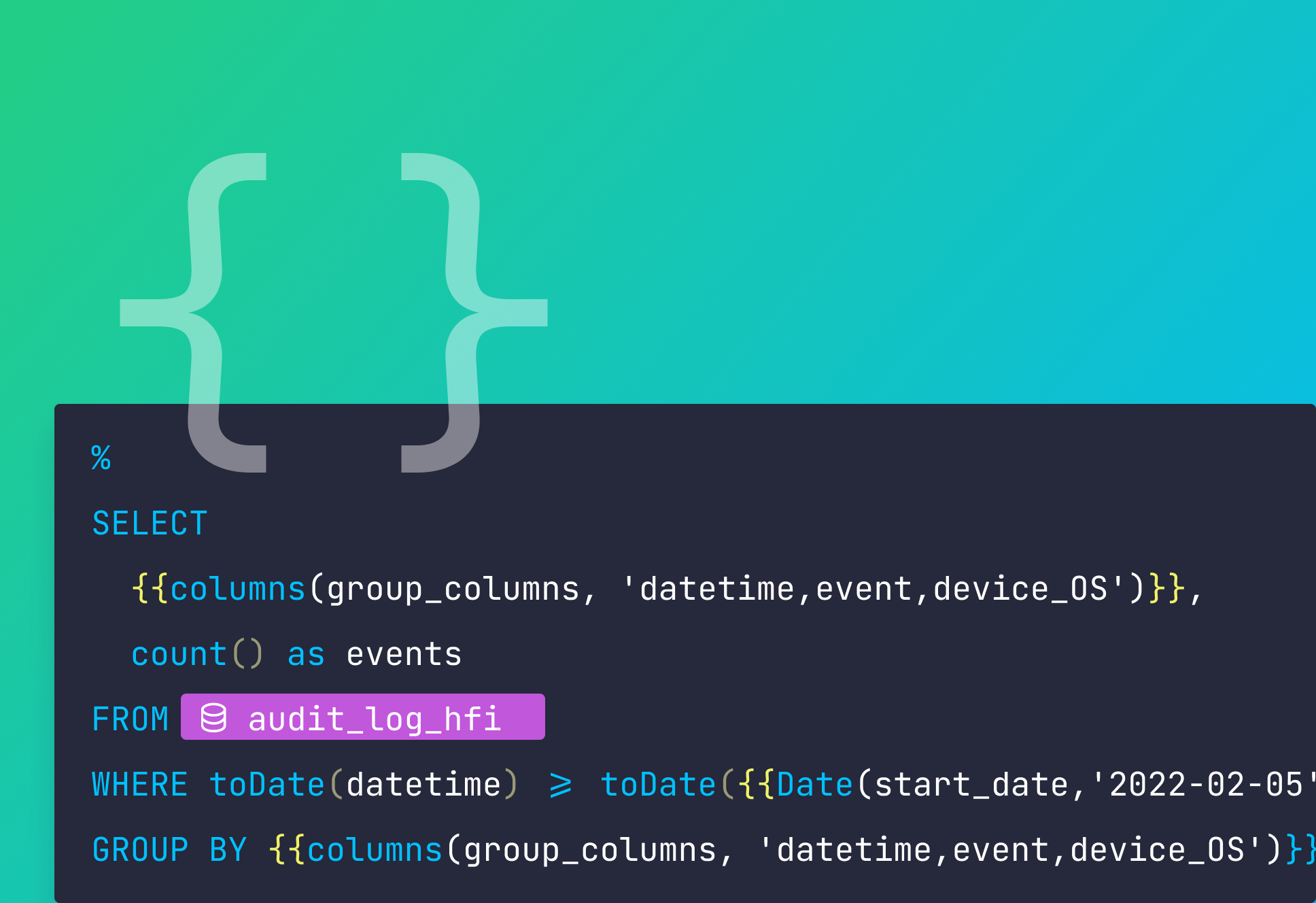
- Added the option to use the same parameter multiple times in a node - it would fail before
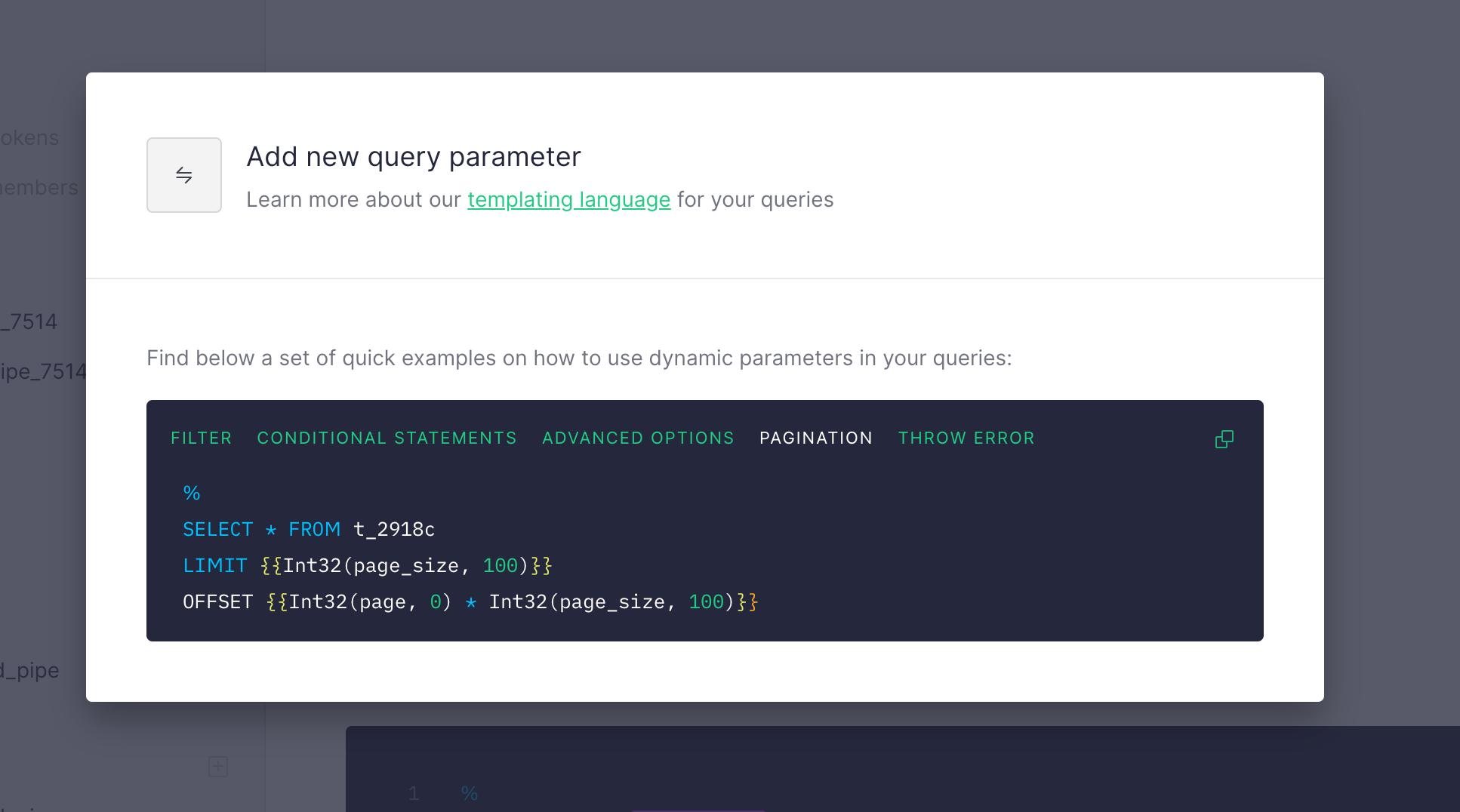
- Added a new snippet example to show you how to add pagination to one of your endpoints
That’s it for now. Follow us on Twitter for more updates and check out our new blog, where we interview some of the biggest experts in the world at solving hard data problems at scale at speedwins.tech.
What are your main challenges when dealing with large quantities of data? Tell us about them and get started solving them with Tinybird right away.