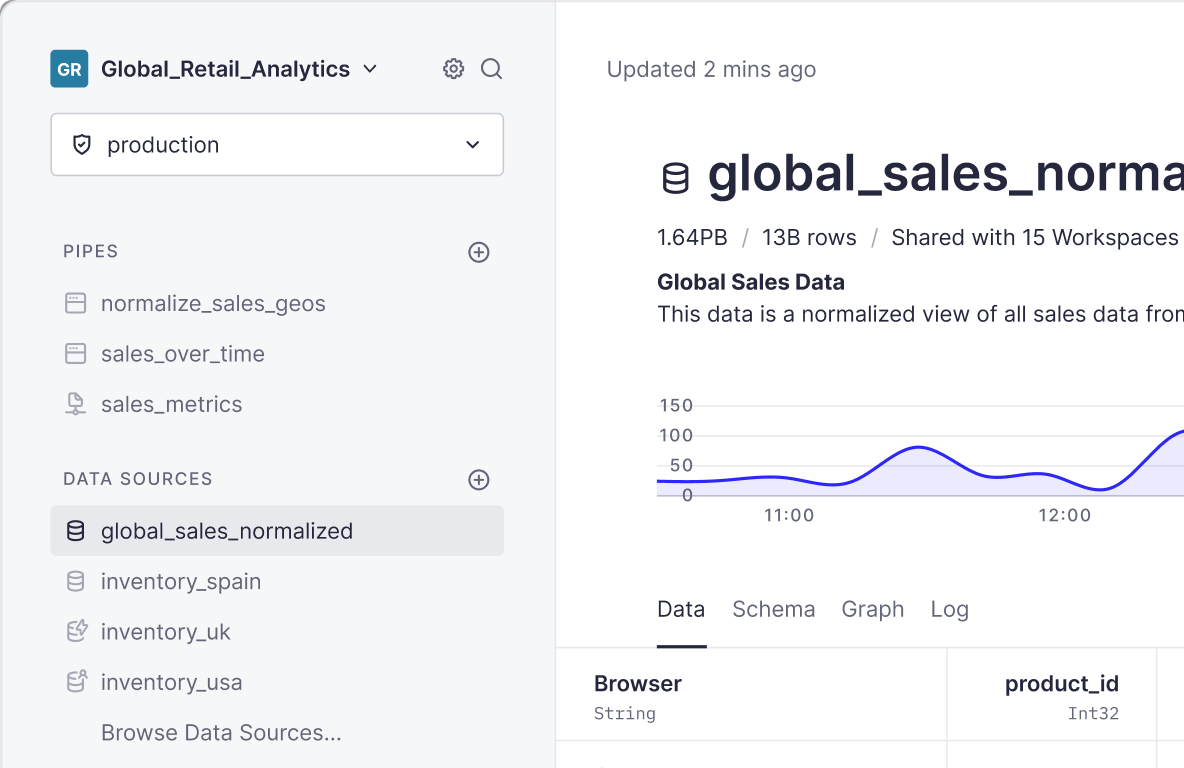
We believe in the value of providing an amazing Data Ingestion experience. After all, it’s what initiates everything: before you can do anything of value with Tinybird, you need some data in your account.
And because we know how challenging data ingestion can get at times, we really want to offer our users a seamless data ingestion experience.
When you are in the midst of working with big datasets, you often find out incoherent data types across the rows for a given column. Or that some rows are containing null values that weren’t expected, or even that the file you are ingesting is missing a column altogether.
Many ingestion problems are easy to solve once you identify them, but they are often hard to detect when working with terabytes of data: it can be like finding a needle in a haystack.
We have developed several improvements in our ingestion process. We believe these changes will make it easier to ingest billions of rows in a reliable and flexible way, without sacrificing speed.
Since there’re many topics to cover, we’ve decided to write a series of posts to talk about them.
In this first one, we’ll focus on how to deal with error responses to be able to identify why and when an ingestion process has failed.
Error feedback on ingest
Ingestion may fail for many reasons: the provided data URL may be incorrect, the data may have encoding problems, or maybe you’re using the wrong ingestion mode to ingest a very large file.
There’s more than one way to ingest data files with Tinybird: you can ingest a remote file via its URL, but you can also upload local files. One of the main differences between these two methods is that the first one will launch a job. Sometimes there might be another job running, so the import has to wait. Therefore, the response when importing via URL or a local file is going to be slightly different, because in the first case you’ll need to be able to check the status of the job: whether it’s waiting, running, done, or if maybe there has been an error.
An import response, regardless of whether data has been ingested using a local file or through a URL, will always contain the following information:
- Information about the
datasource. - The
import_idto be able to track this particular data ingestion. - The
job_idto be able to track the job if data was ingested from a URL. In this case, thejob_idand theimport_idwill have the same value. - A summarised description of the
error, if any - A list of
errors, if any, because it’s possible that more than one error has occurred - The number of
quarantine_rows, if any were sent to quarantine due to some discrepancy in the data types - The number of
invalid_lines, if any were not ingested at all

In both cases, the returned error is equivalent. As a user, I expect an API to be consistent, which is one of the rules we strive for in order to provide a good user experience.
In fact, all of these error messages and improvements apply also to ingestion via Kafka, where changes to the schemas could otherwise easily derail any integration.
You can find out more about error messages in the API documentation
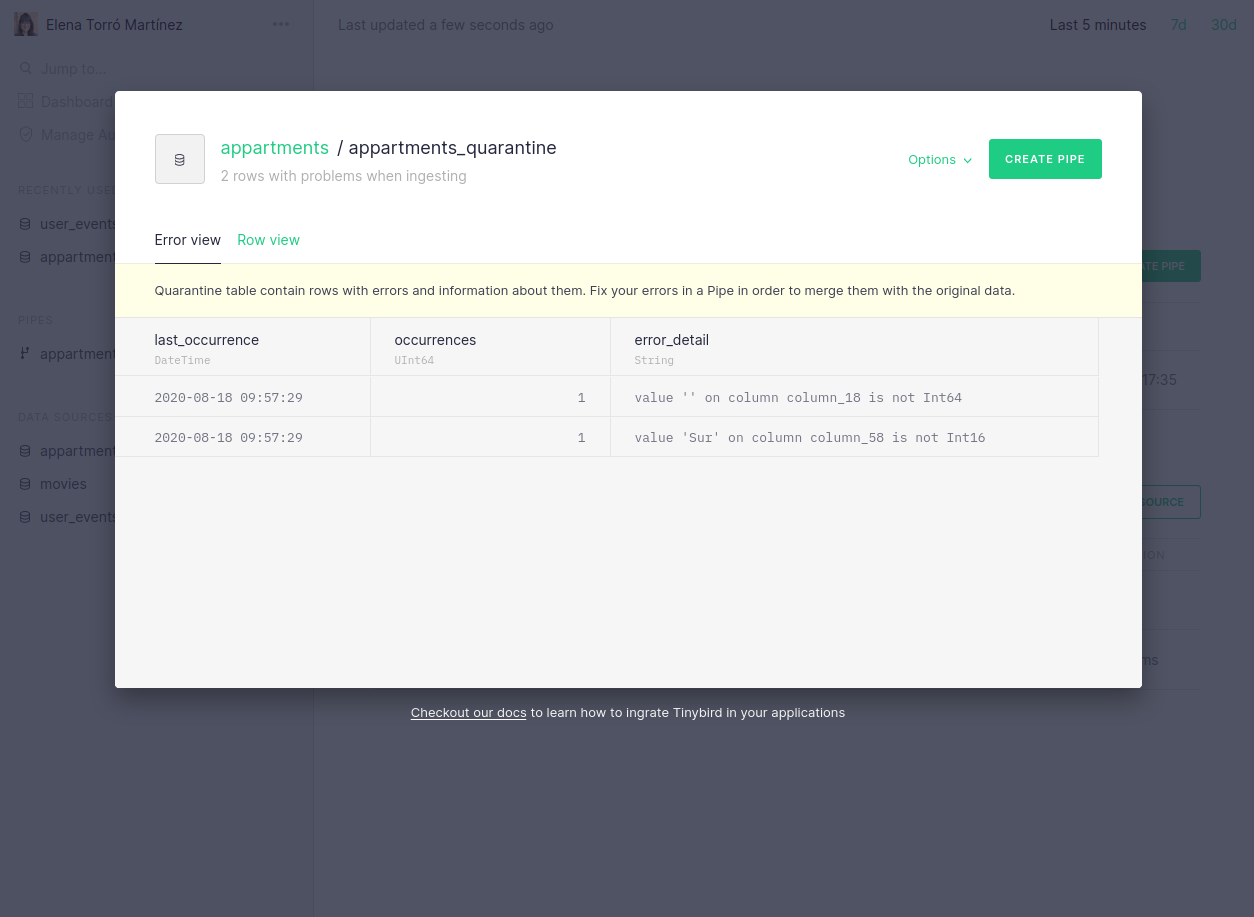
We’ve also brought these API changes to our UI, to provide a better understanding of why an ingestion process may have failed and, consequently, to make it easy to fix. It’s now easier to navigate and identify which rows were moved to quarantine, but there is also a descriptive message when there has been a parsing error:
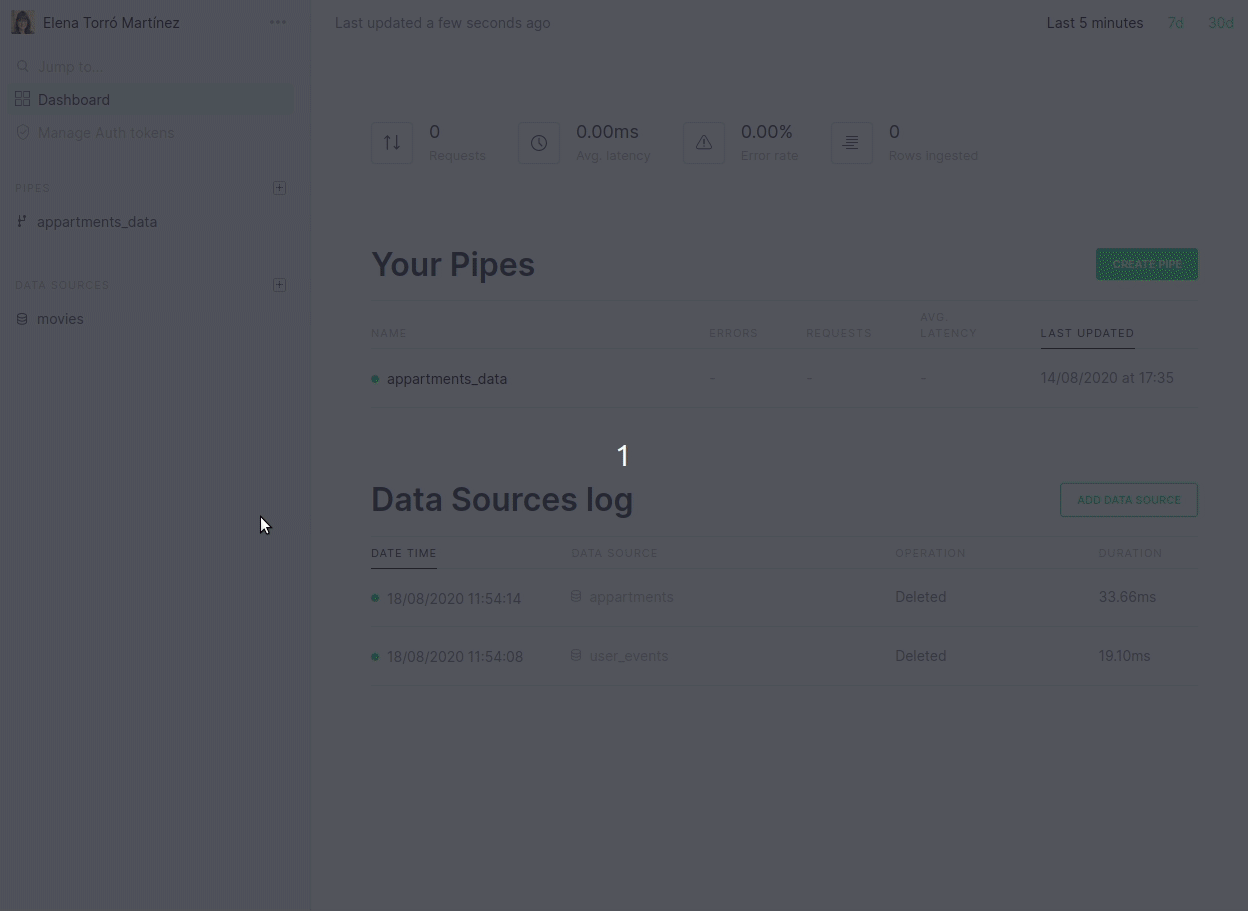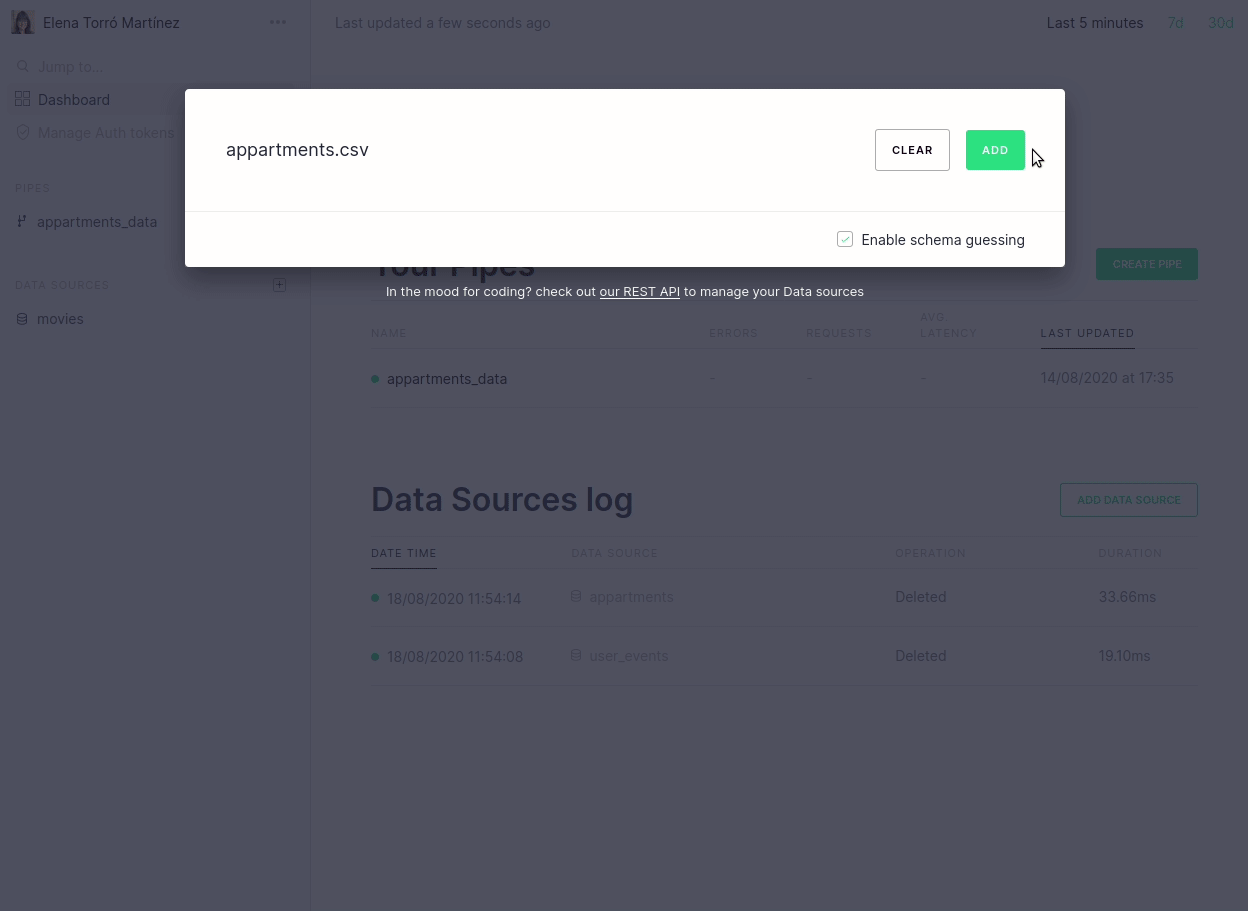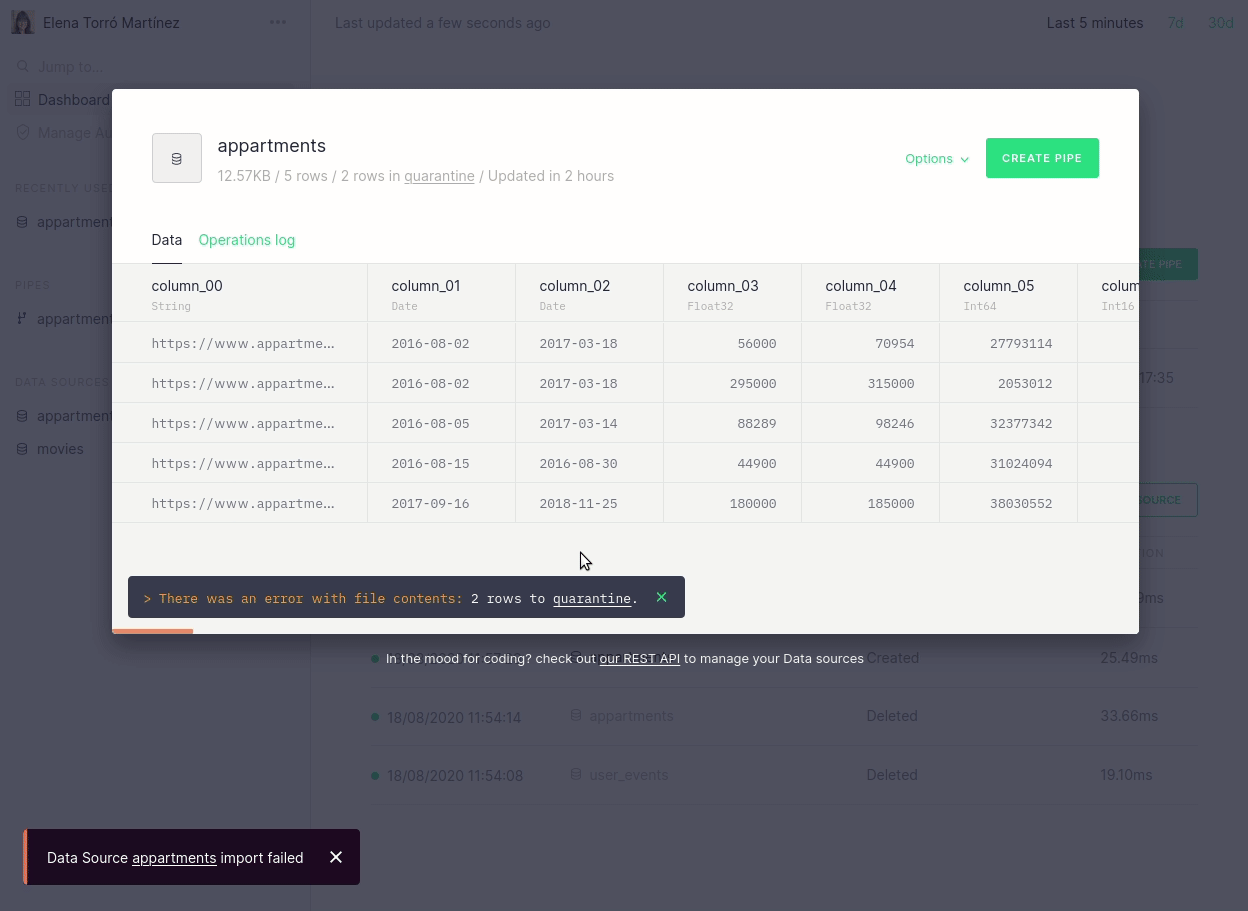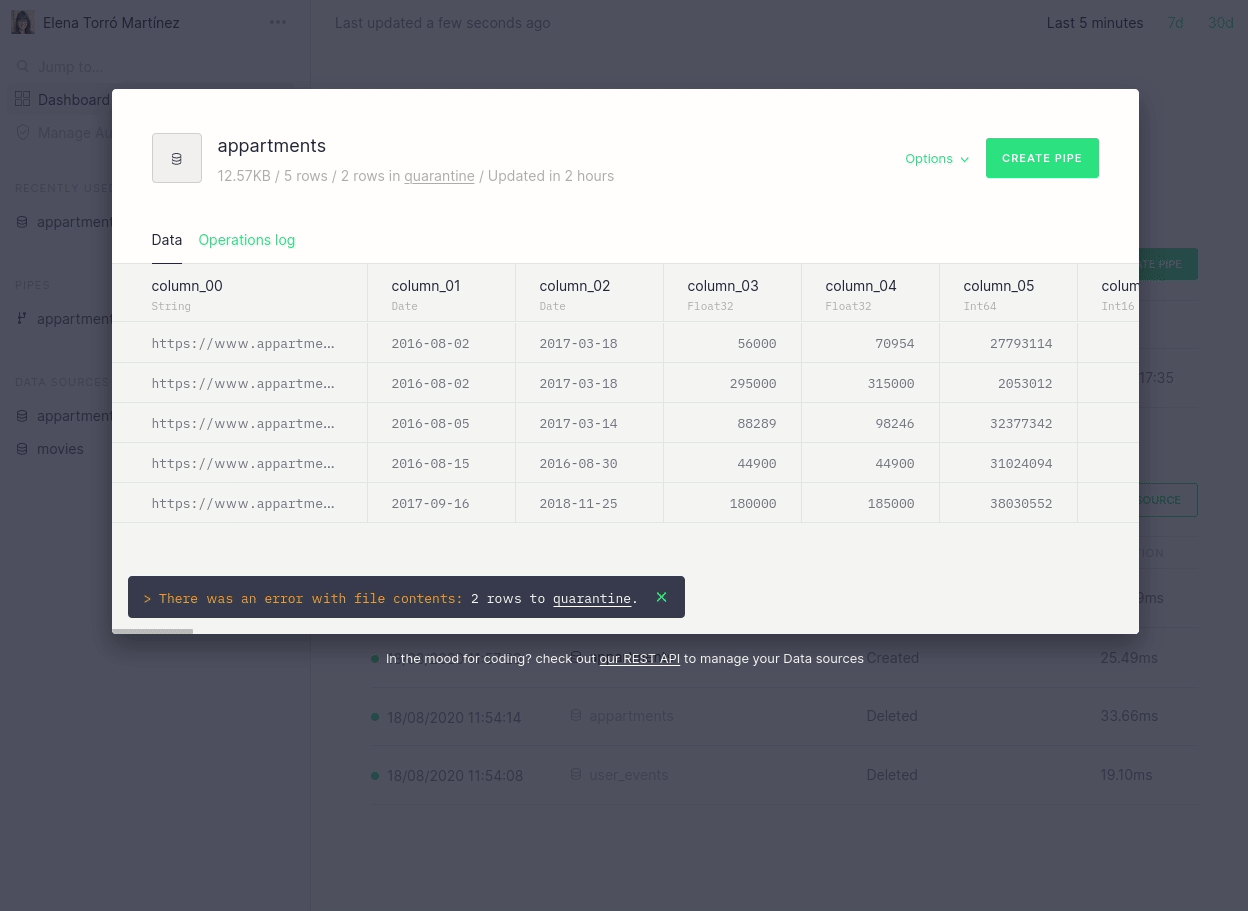
Furthermore, we now link directly from the dashboard to the actual errors that may have occurred:
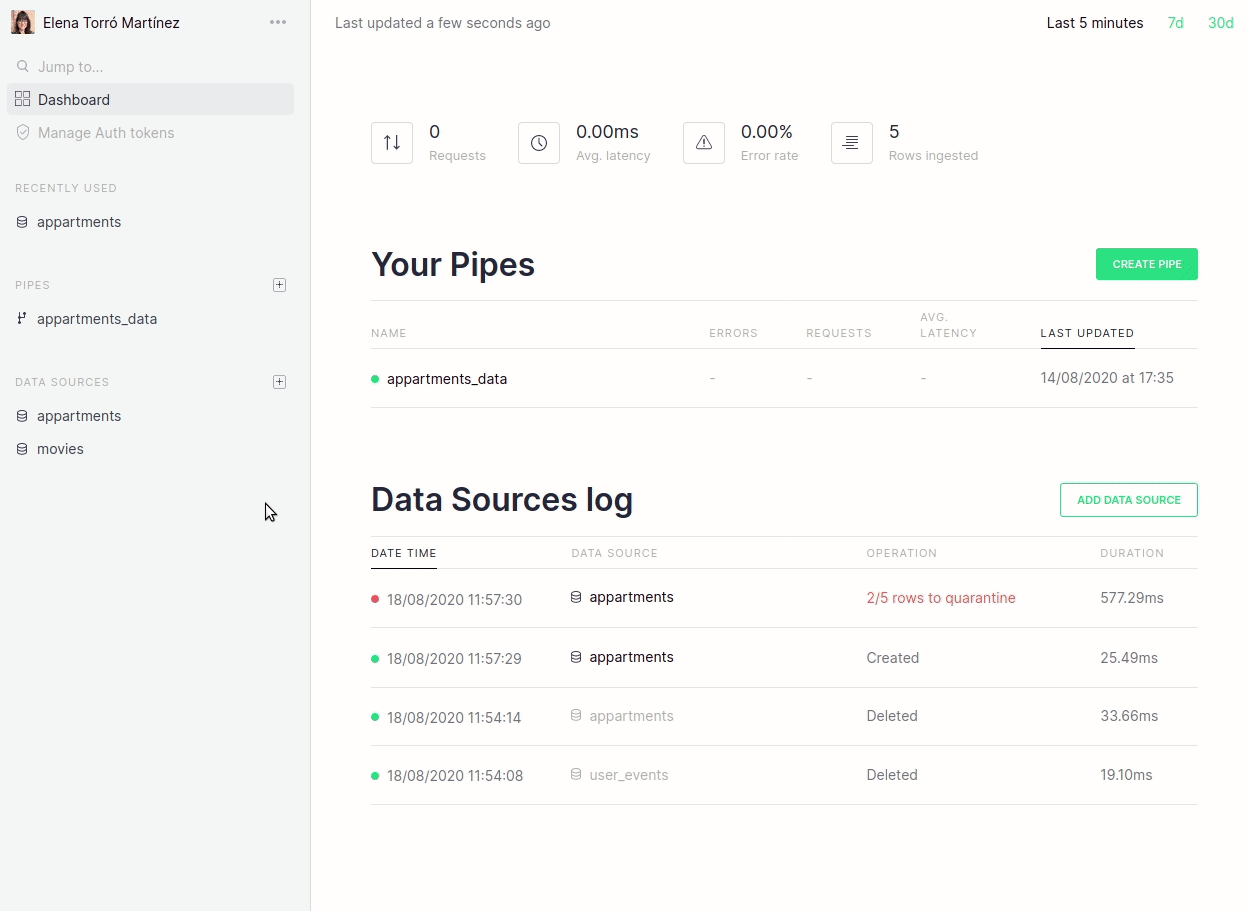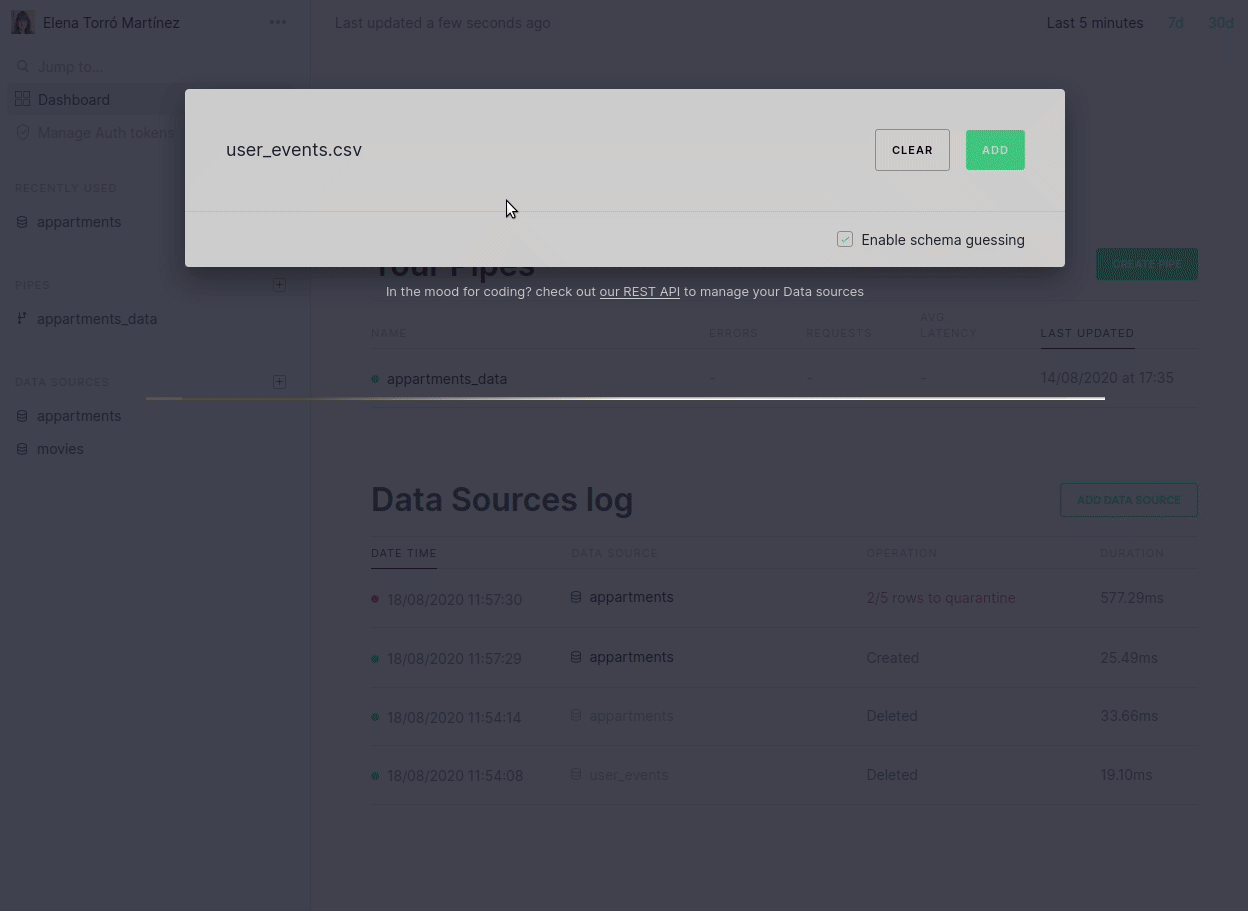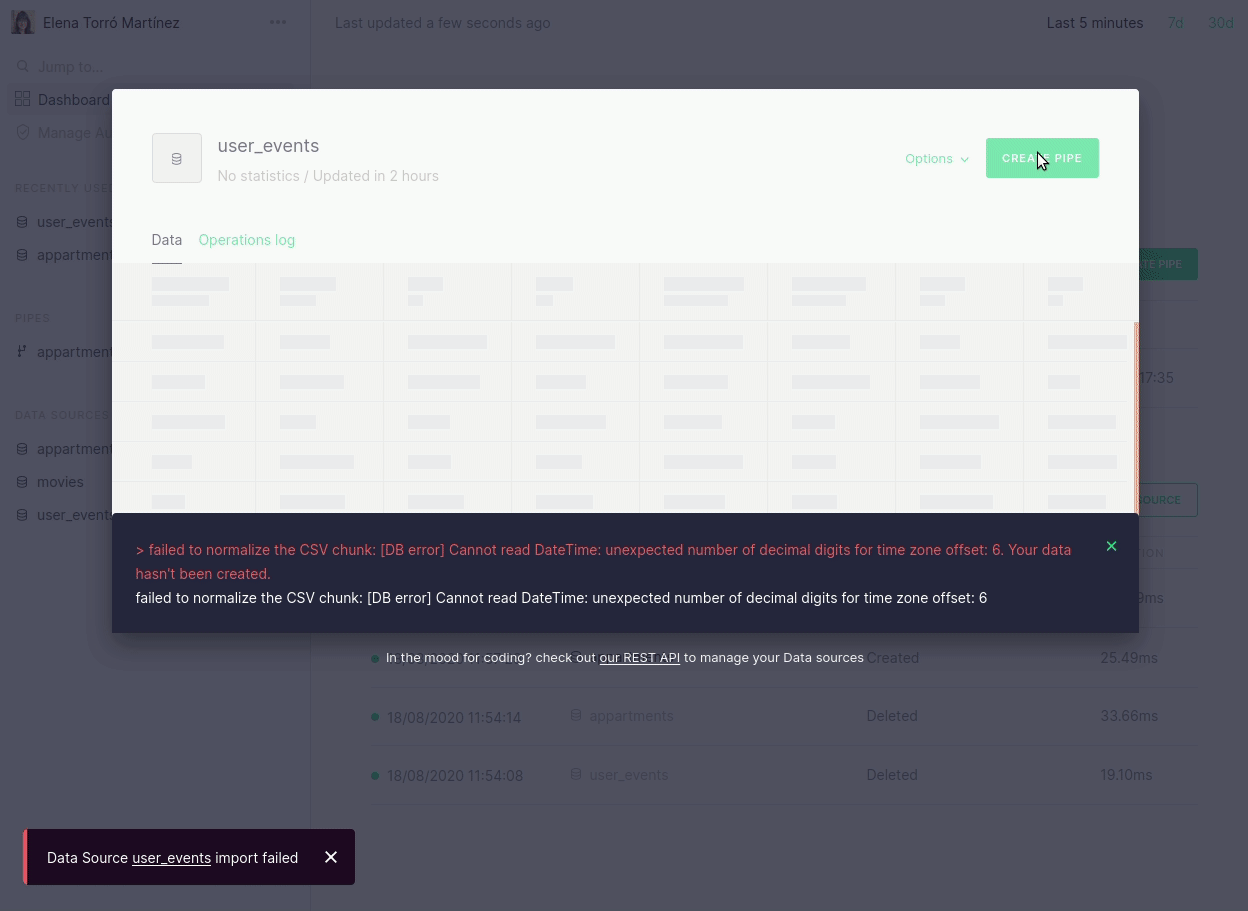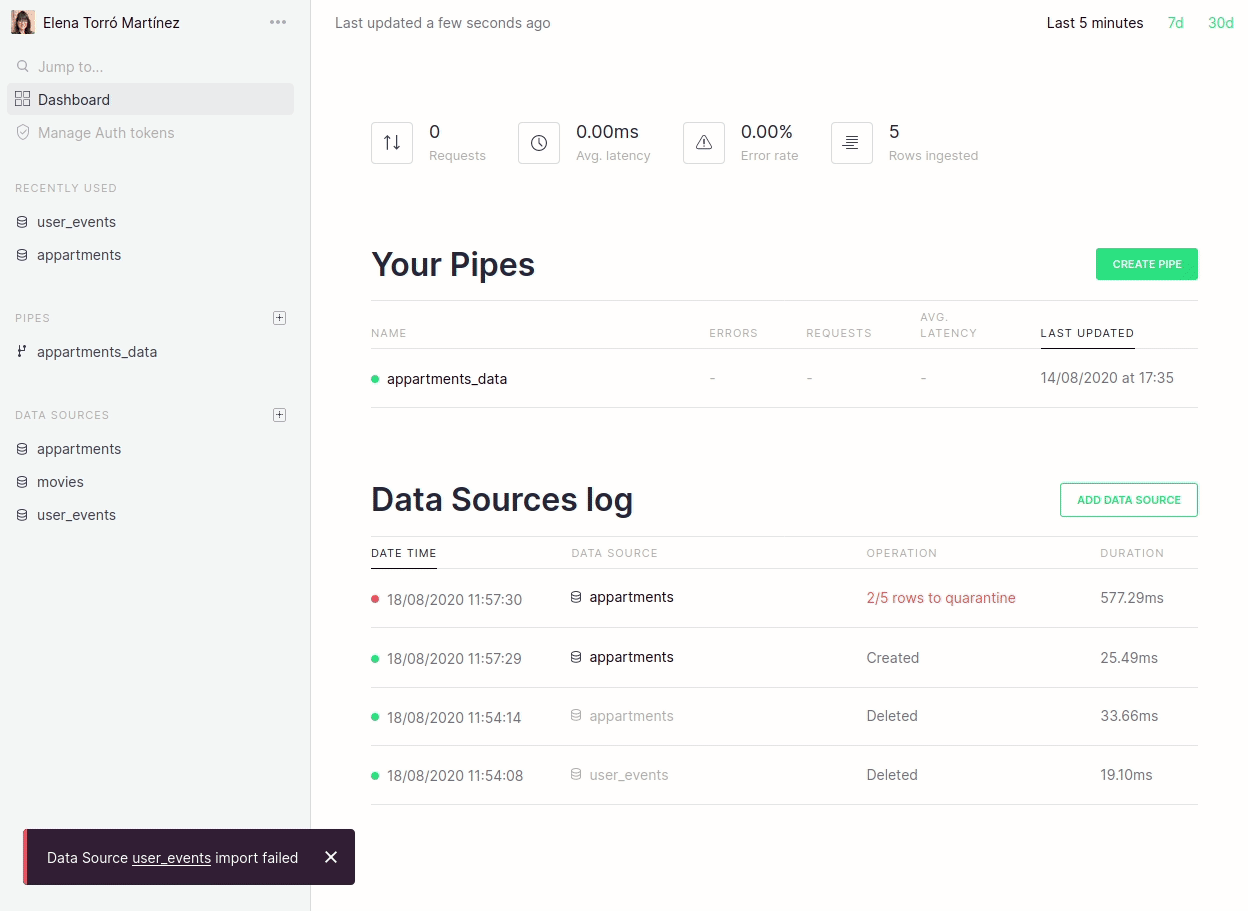
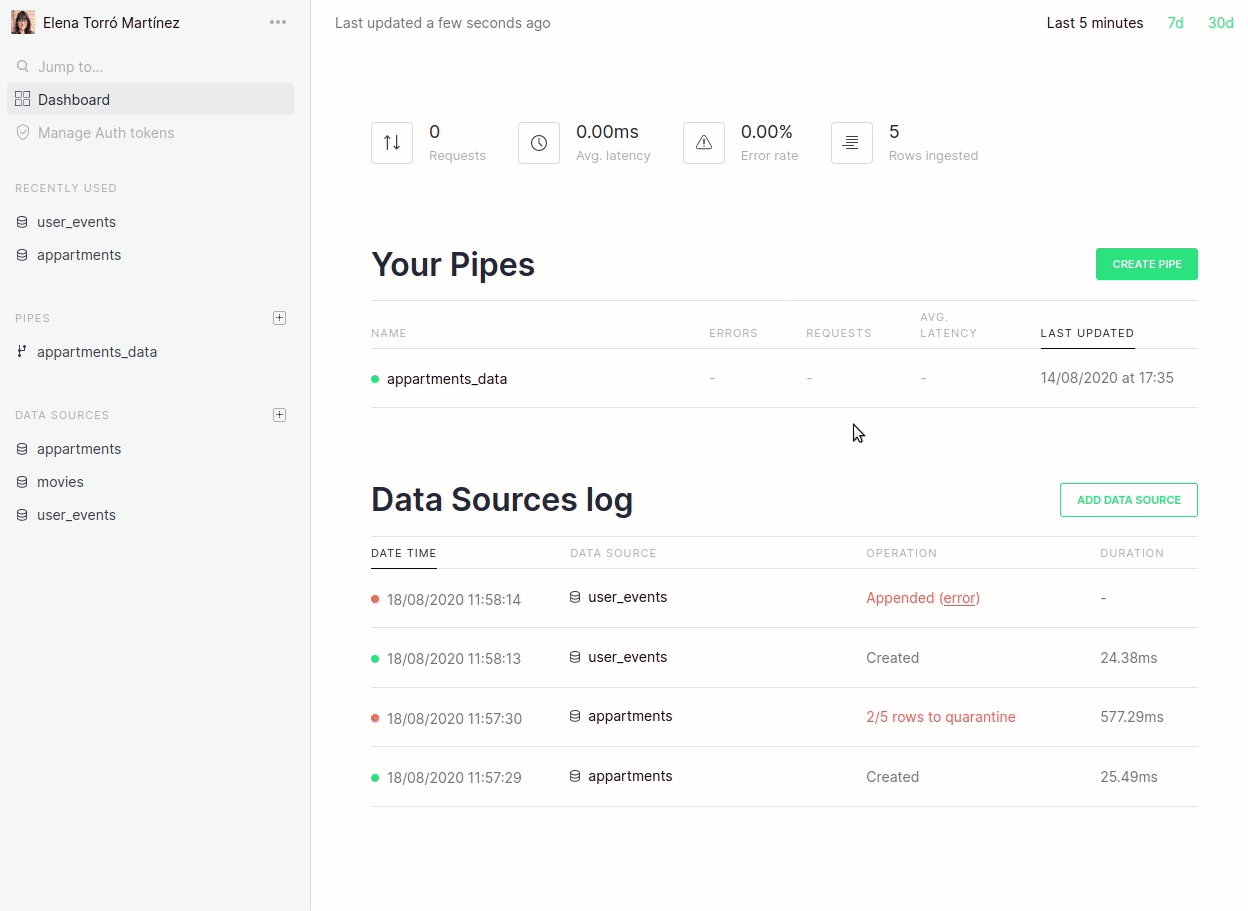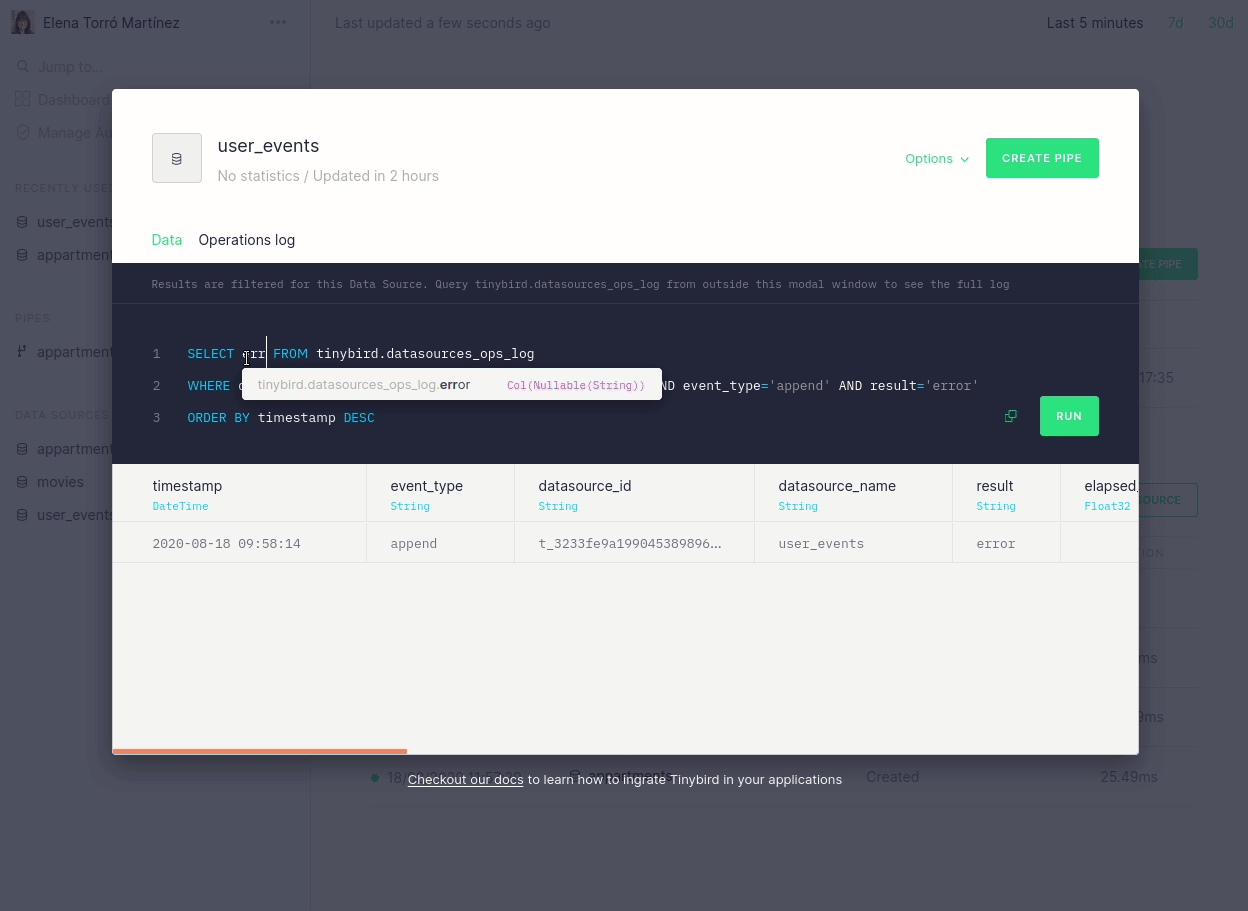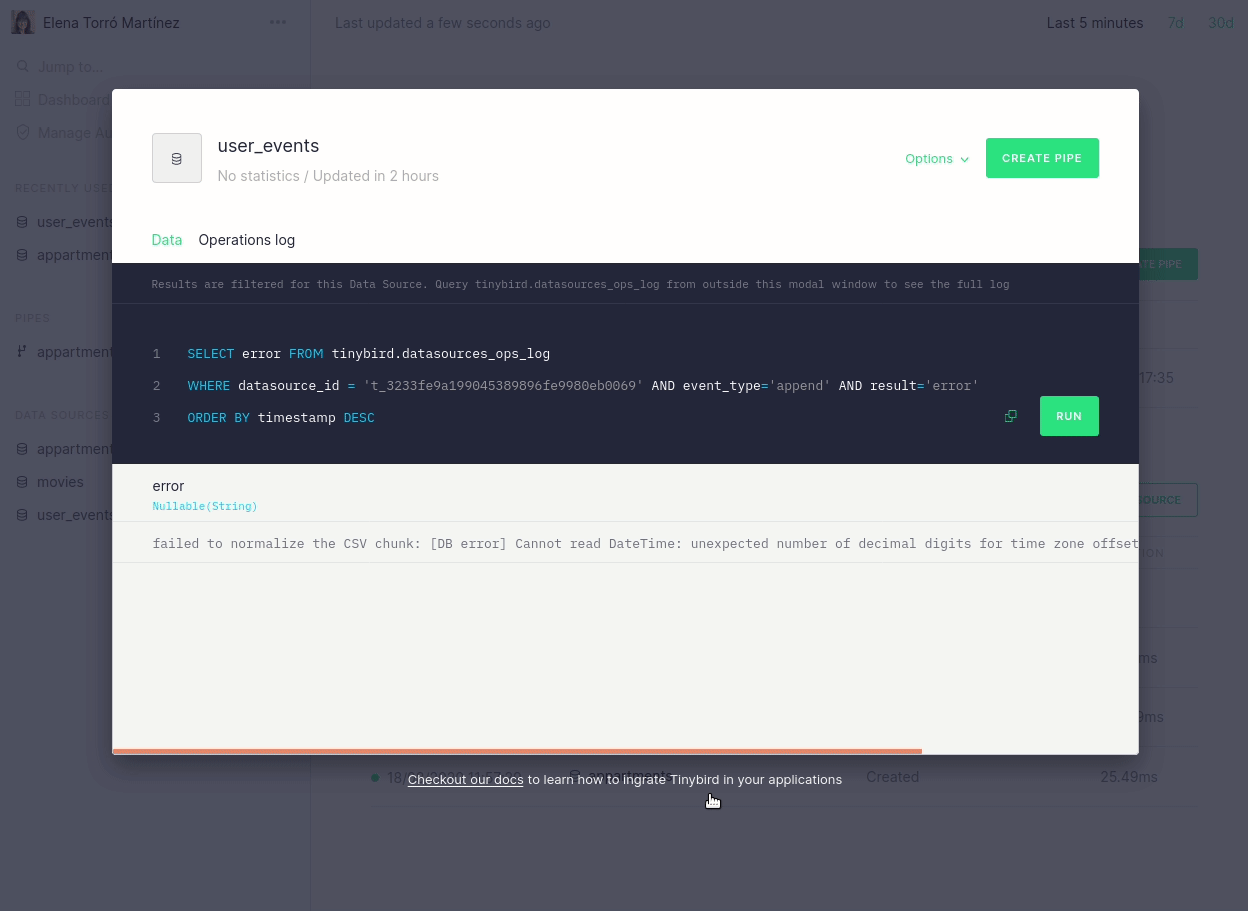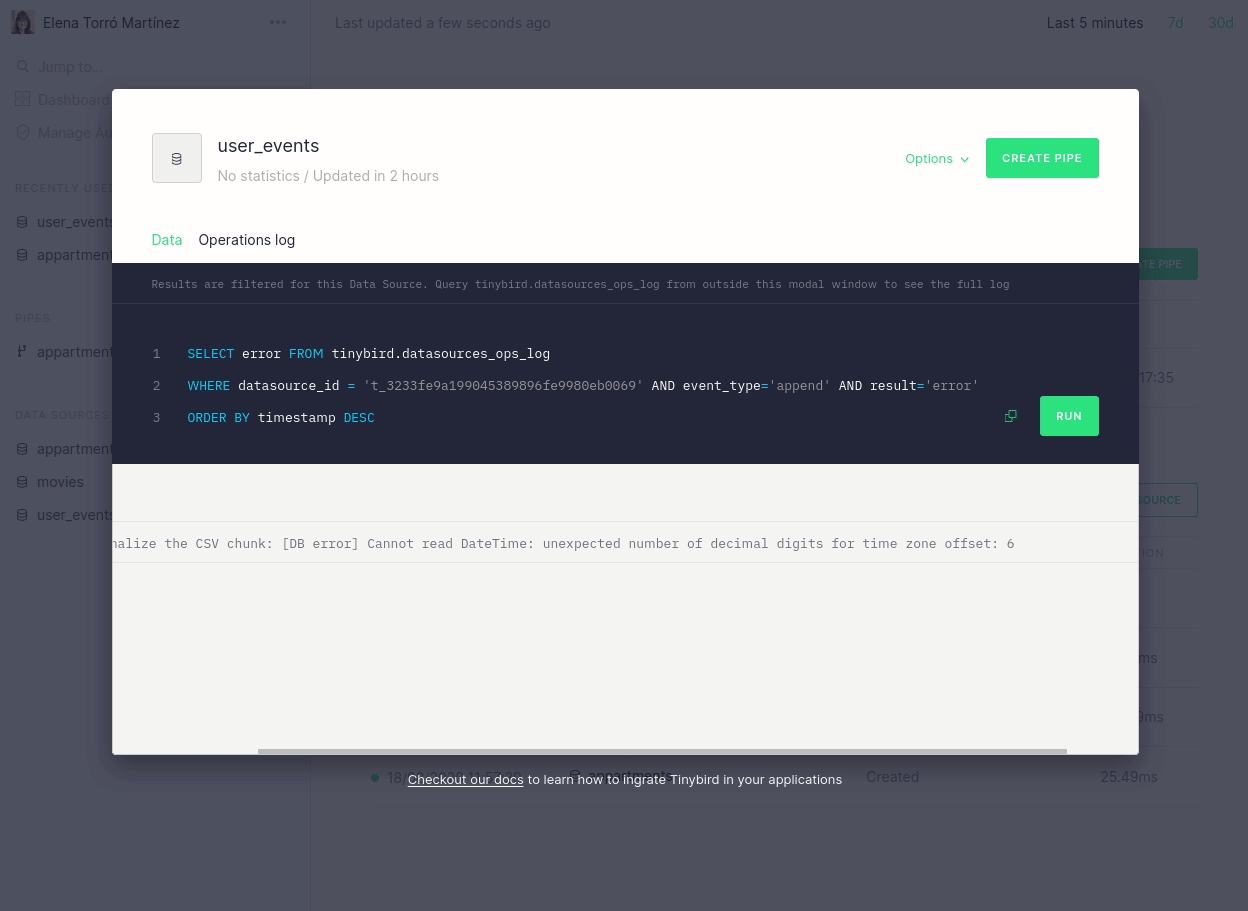
We are really focused on making this process revolutionary simple and the changes above are just the first step. In future blog posts we will talk about more improvements, such as fine-tuned guessing, more control over quarantine tables, ability to disable guessing for certain scenarios and more.
What are your main challenges when dealing with large quantities of data? Drop us a line and let us know!