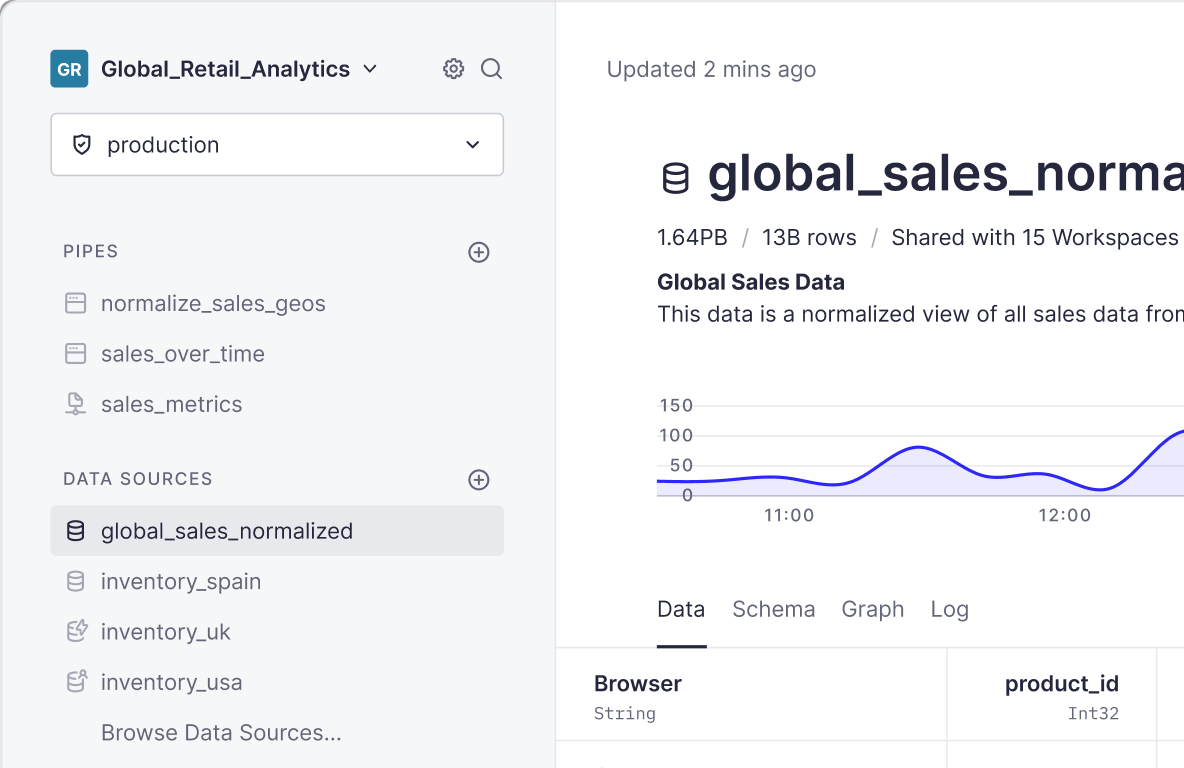
Apache Kafka has quickly become the de-facto standard for capturing events data in real time. Part of its popularity lies in its ability to separate the collection of huge volumes of data and the processing of that data. This means you don’t have to decide upfront how you will deal with that data once you capture it: you can start collecting it and then progressively tackle different use cases.
However, Kafka comes with its own set of problems when it comes to consumption. Volumes can be huge, data within the topics evolve with time, building a consumer for every use case requires specific knowledge of the data and the technology, etc.
Pushing events to a managed solution like Confluent is the easy part. Making some queries with kSQL on some topic is also easy, as Confluent also offers a managed kSQL service but going from there to having a data product that lets users get insights on that data in real time, with low latency and high concurrency, is the real challenge and that’s when you should turn to Tinybird.
Productizing Kafka streams
Kafka is not meant to be a long-term storage solution, so you will need to store your data somewhere else. In many cases, you will also not want to store all individual messages, but aggregations of computed metrics from them. So the first step will be creating a Kafka consumer that reads the data you want from a specific topic, does any transformations required, and writes the results somewhere else.
An analytical database like ClickHouse is a good candidate for this, as it is one of the fastest databases to filter and aggregate huge amounts of data. ClickHouse also lets you create materializations on your data so that aggregations are as fast as they get.
But the challenges don’t end there. If you want to create API endpoints on top of the data stored on ClickHouse, you’ll also need to create a backend application that reads from ClickHouse, handles security properly so that no data breaches happen, and is performant enough to be used by a large number of users. These API endpoints should also be documented so that the developers that will consume them know how to call them and what they return. That’s why you need Tinybird.
Using Tinybird’s Kafka connector you ingest events from a topic directly to a Data Source. The connector is optimized to sustain high data loads so that you can easily scale-up your project.
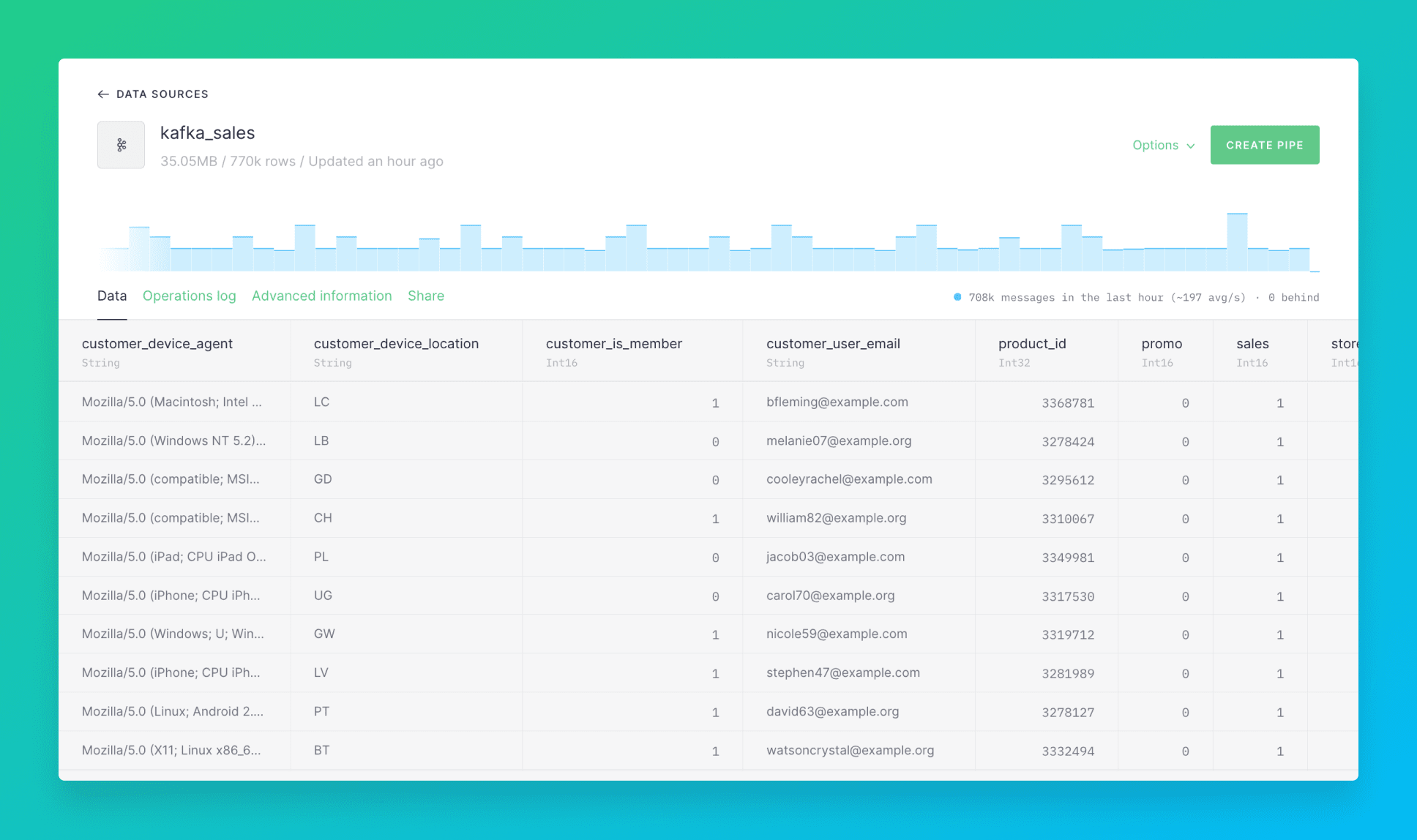
You can then run queries, transform data with Pipes and create materializations to pre-aggregate data on the messages ingested with the Kafka connector without having to worry about maintaining or scaling the underlying infrastructure. Tinybird does it for you.
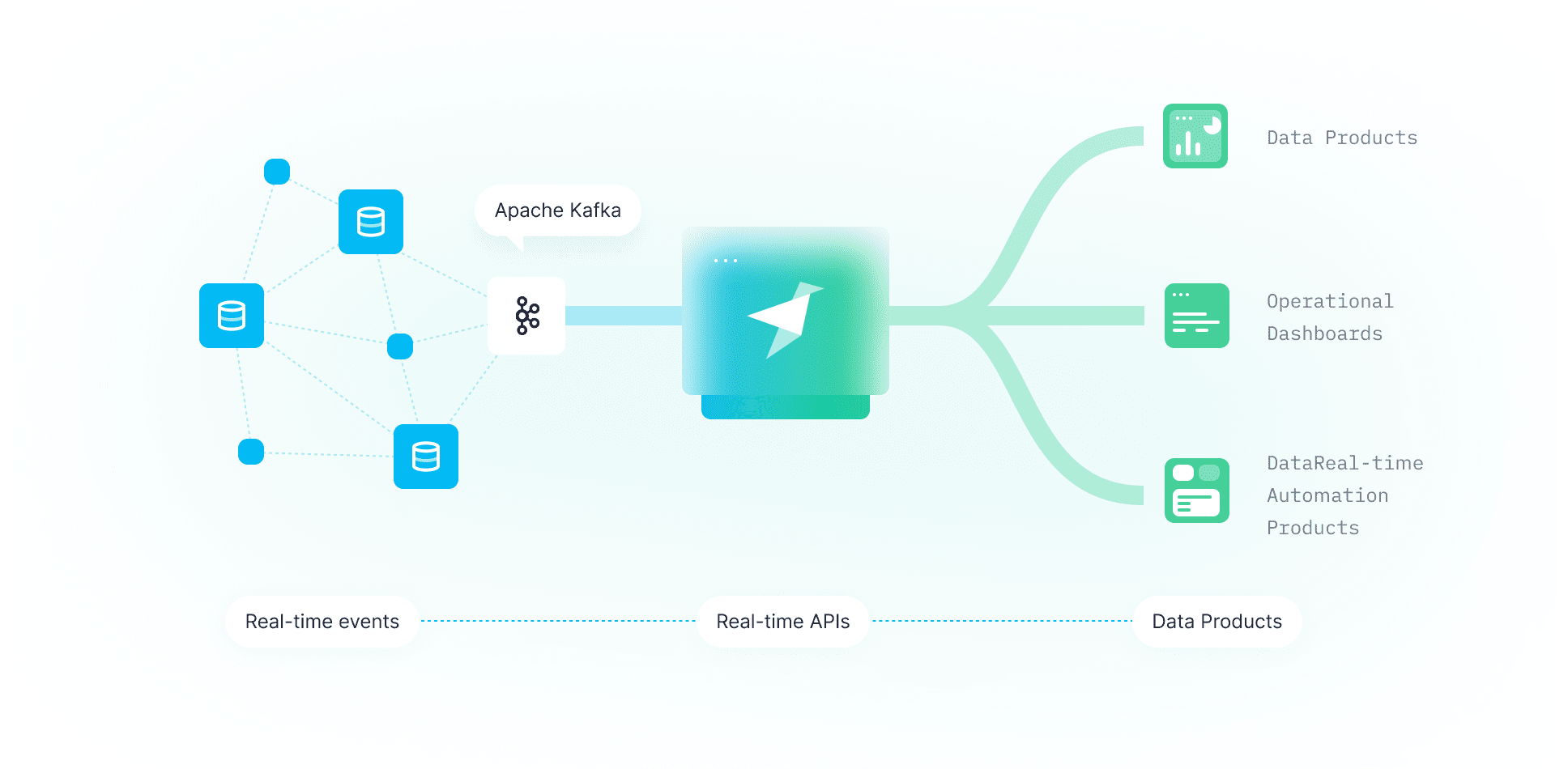
And most importantly - you can create secure, dynamic endpoints directly from your queries, with a shareable documentation page that is generated automatically. This process that would have taken a backend developer weeks now only takes seconds. And this not only means that you can do the same in less time but also when getting answers from your data becomes orders of magnitude faster then things that were not possible before become possible now, enabling developers to change entire industries.
ClickHouse is the right backend for Kafka and Tinybird is the right publication layer for ClickHouse, so the three solve (among others) the problem of creating analytical apps out of streaming and historic data at any scale. Here’s how you do it with Tinybird:
The Steps
Let’s see in detail how to go from a Kafka stream to a data product running from an API endpoint. This example uses synthetic sales data from an ecommerce site.
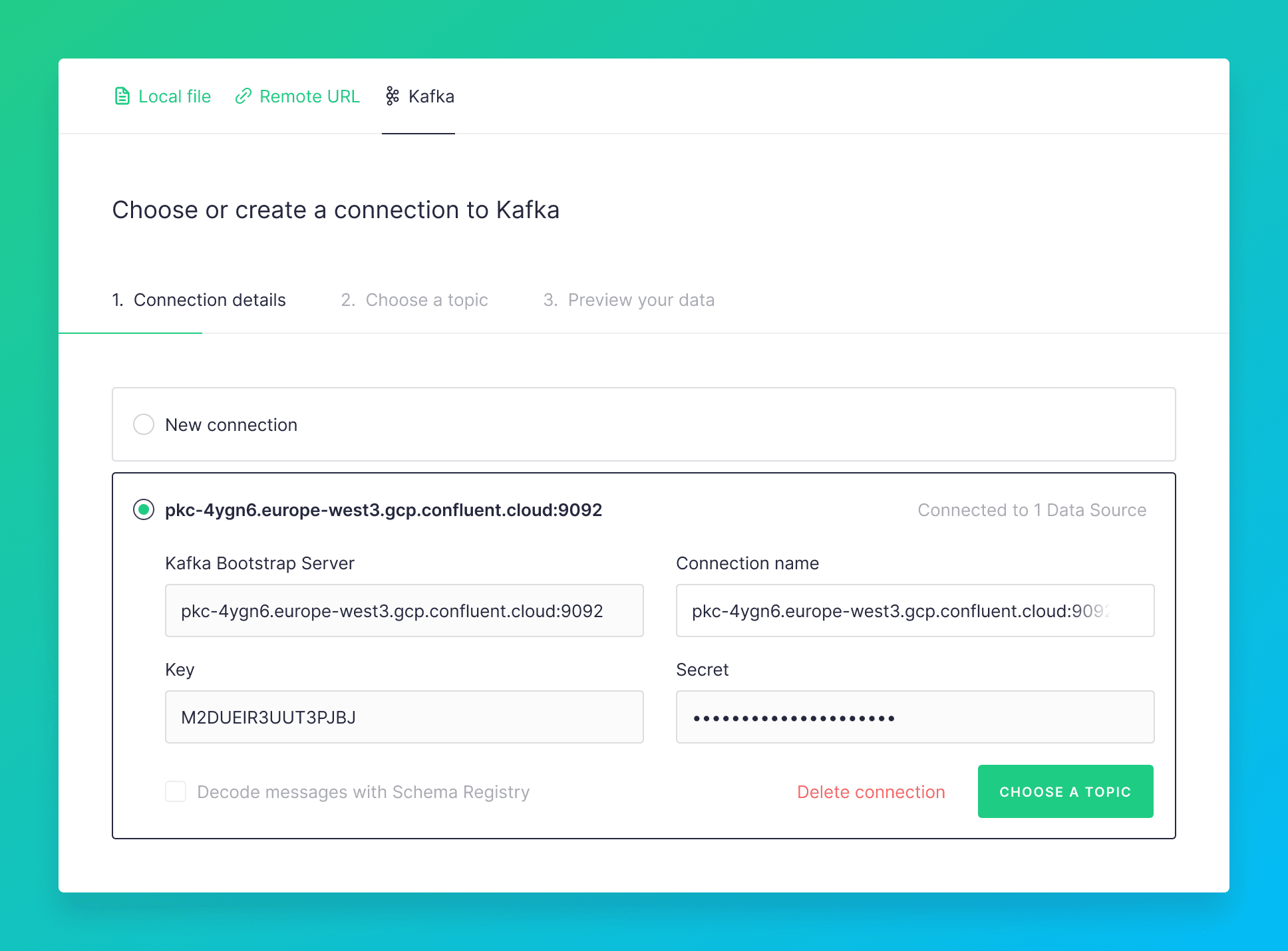
1. Connect to a Kafka stream from Tinybird’s UI
Tinybird’s UI steps you through connecting to your Kafka stream by asking for a minimum of just five pieces of information:
- Kafka Bootstrap Server - in form mykafka.mycloud.com:9092
- Key - for example, API_KEY in Confluent Cloud
- Secret - for example, API_SECRET in Confluent Cloud
- Topic - select from the list of existing topics on the cluster
- Group ID - for the consumer group
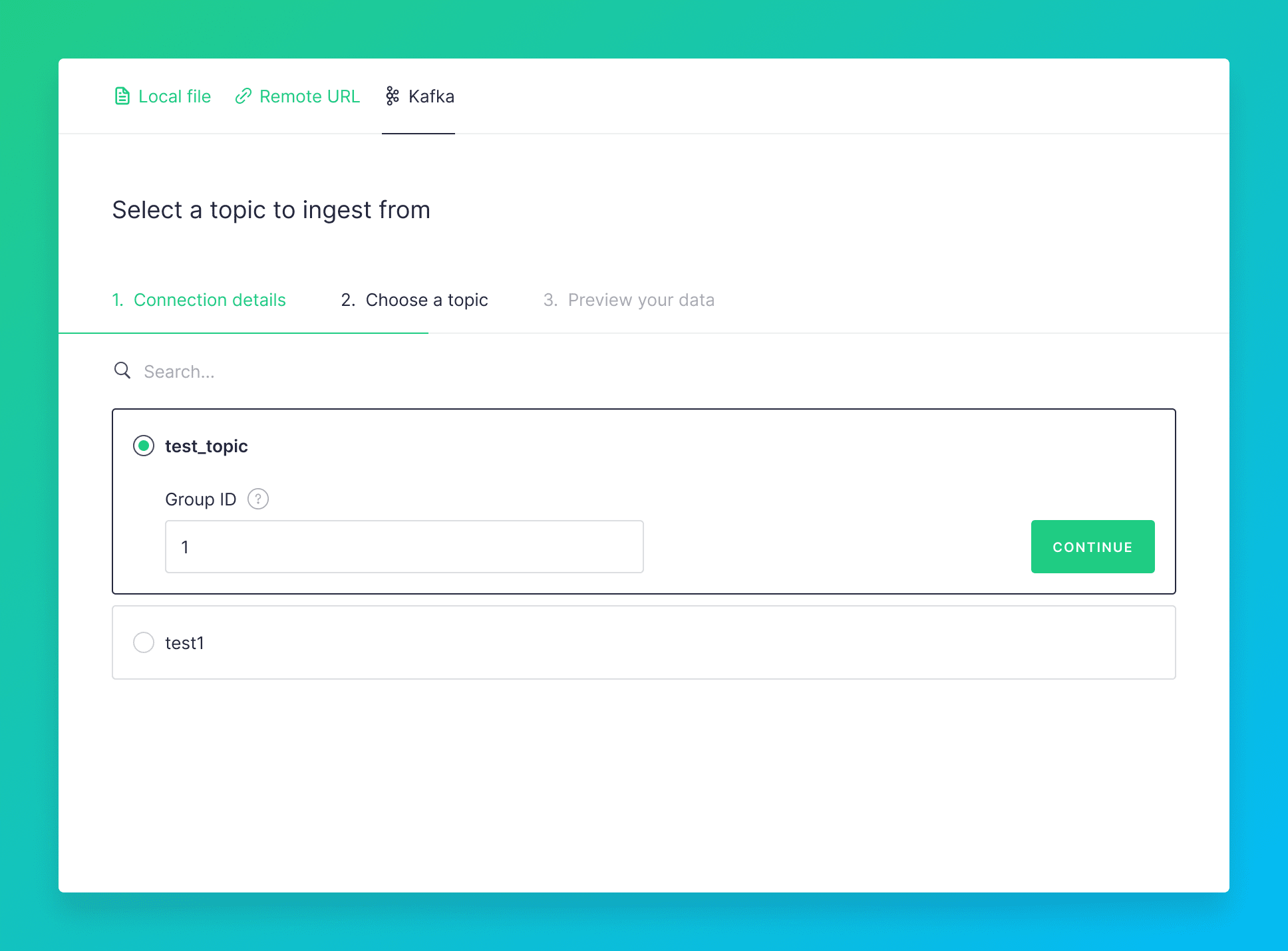
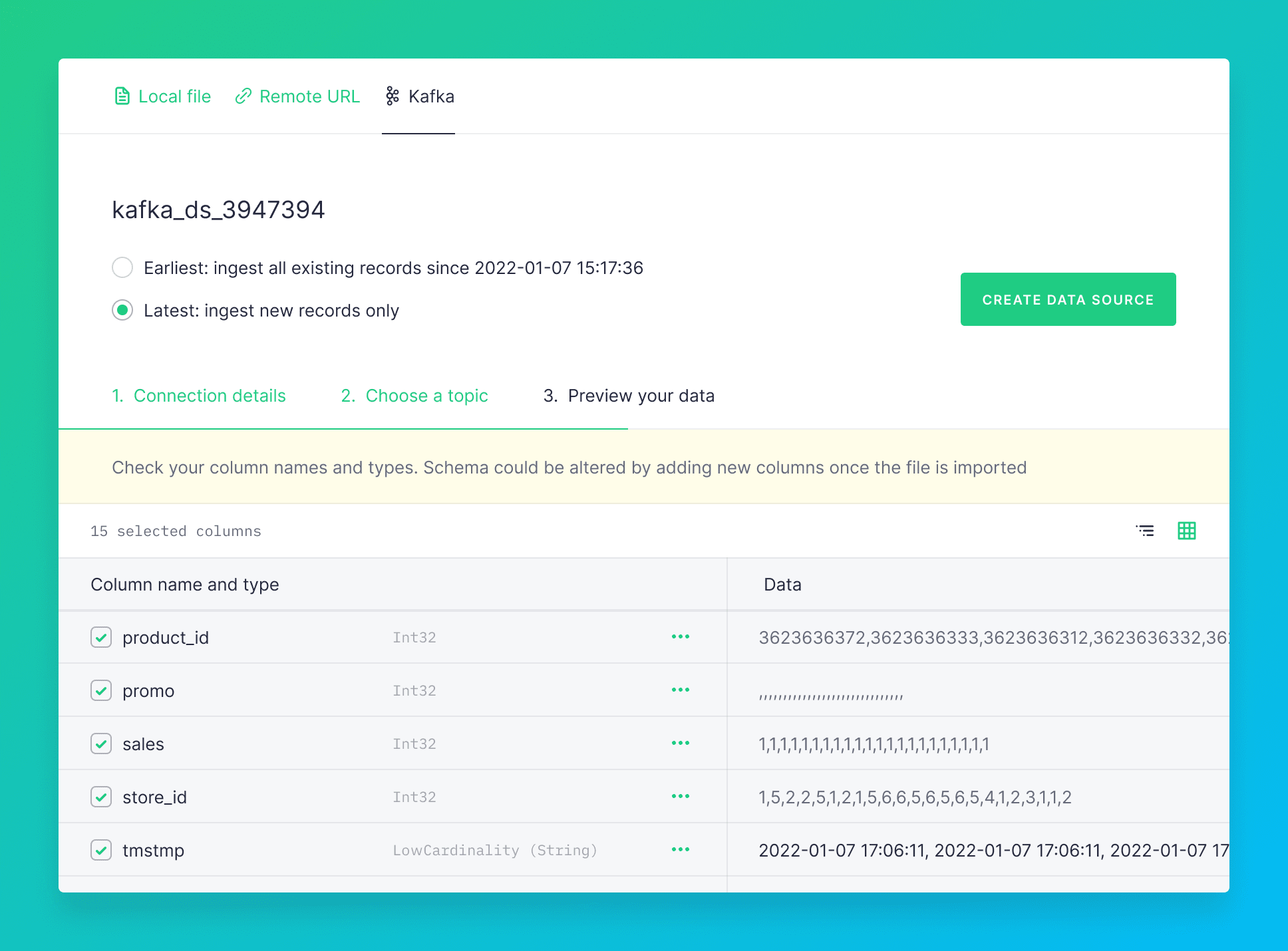
By default only new data is ingested, although there is an option to ingest all existing records.
When previewing your data you can select which JSON attributes you want to turn into columns in the Data Source using the tree view.
For this example, all the columns are kept. The schema is generated automatically by Tinybird. The Data Source has been renamed.
Note that you can also connect to a Kafka stream using the the Kafka connector from the CLI.
2. Create an API endpoint
Here we materialize the sales data, enrich it with product data and run an analysis to find the top selling product in each minute.
Let’s materialize just some of that ingested data into the z_sales Data Source, which will update in real time as new data comes in from the Kafka stream.
We can enrich the data in z_sales using JOIN to other Data Sources, such as products. The JOIN is late in the pipe for extra speed since we join to as little data as possible. The API endpoint can be constantly queried to analyse changes in output as events are processed.
The query in the pipe takes an hour of sales, finds the top selling product in each minute and joins to the product information.
3. Data product from the API endpoint
Here’s a simple dashboard of a chart and table of the top selling product each minute using the API endpoint in Retool. As data is being ingested via Kafka the dashboard can be updated in real time.
If you want to see by yourself how seamless the experience is to consume Kafka data with Tinybird, sign up here or send us an email at hi@tinybird.co. If you already have an account, join us in our community Slack and show us how you are using Kafka streams with Tinybird. Looking forward to seeing you there.