The last weeks have been intense at Tinybird, with lots of new features and product improvements. Let’s explore some of them!
Adding new columns to a Data Source
Now it’s possible to add new columns to Data Sources on Tinybird, without having to recreate them and reingest all the data. It’s supported in the UI as you can see before, and also via the CLI and the REST API.
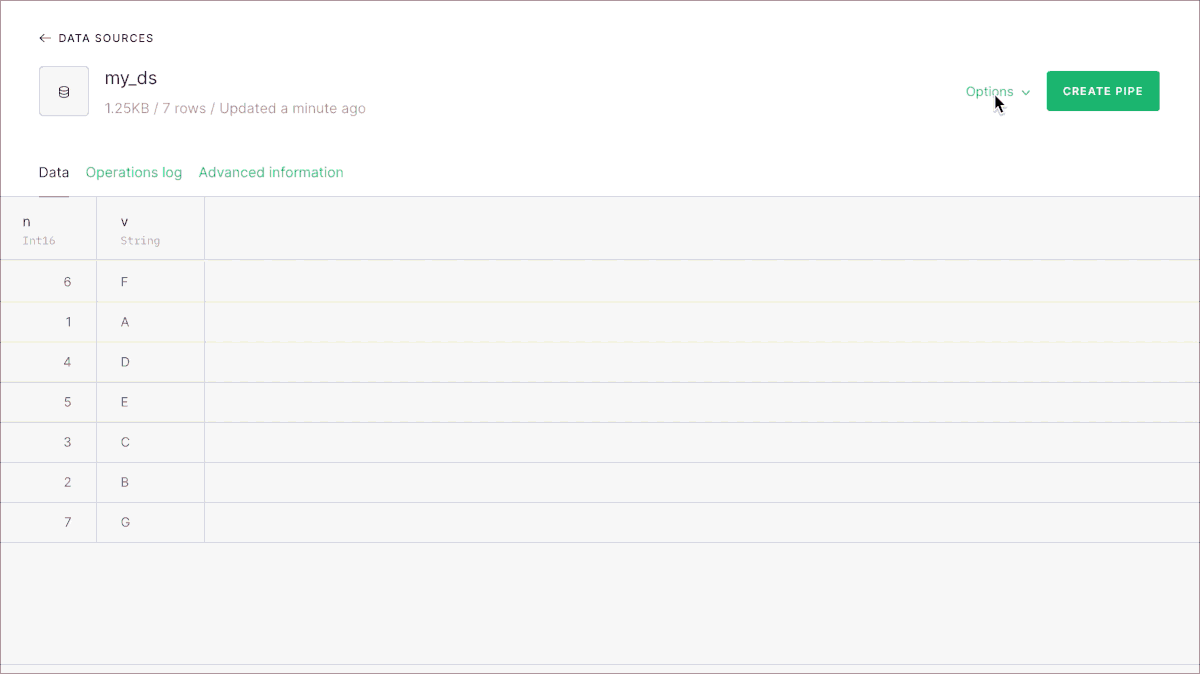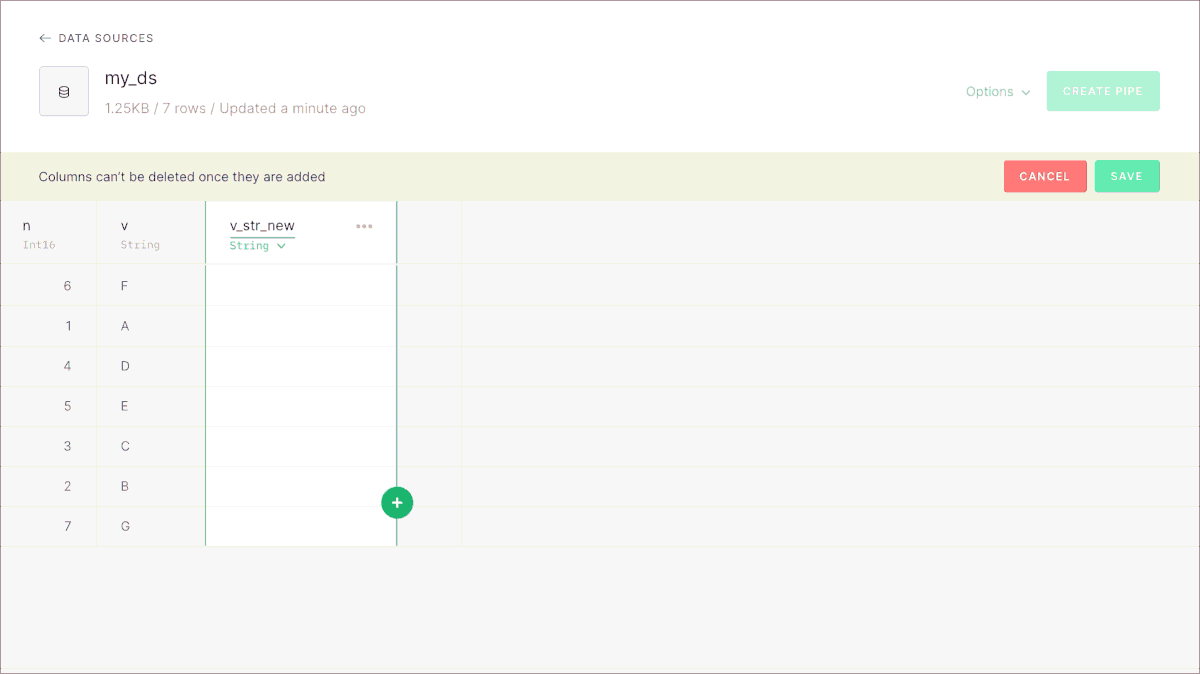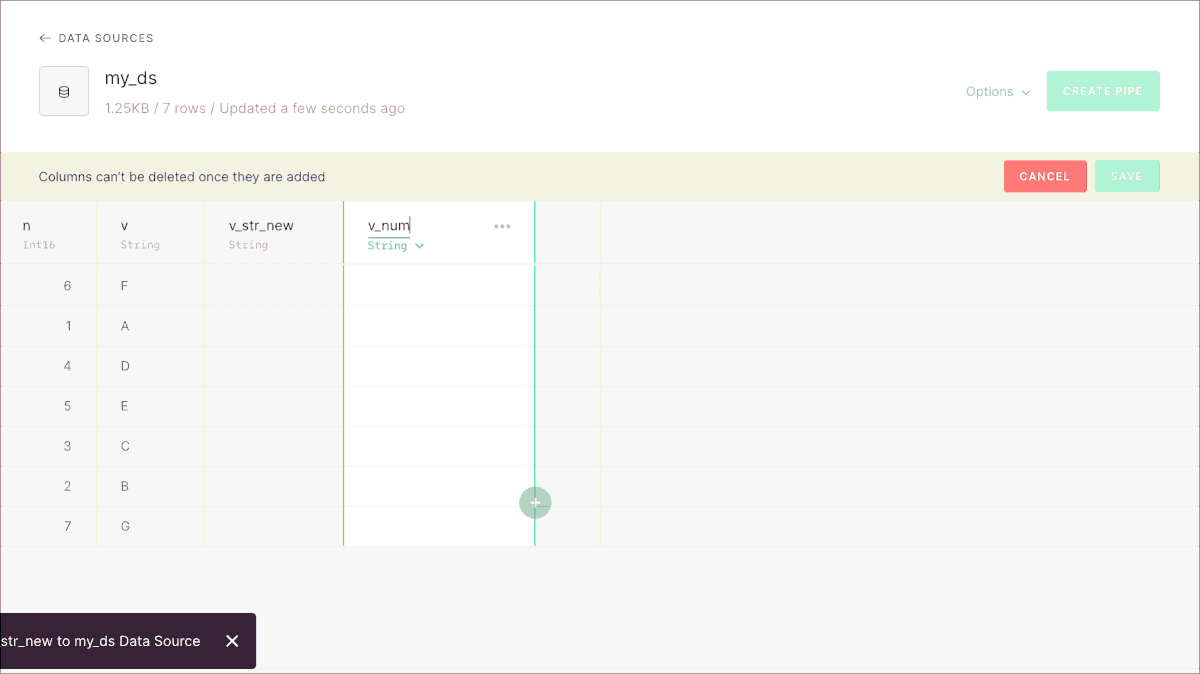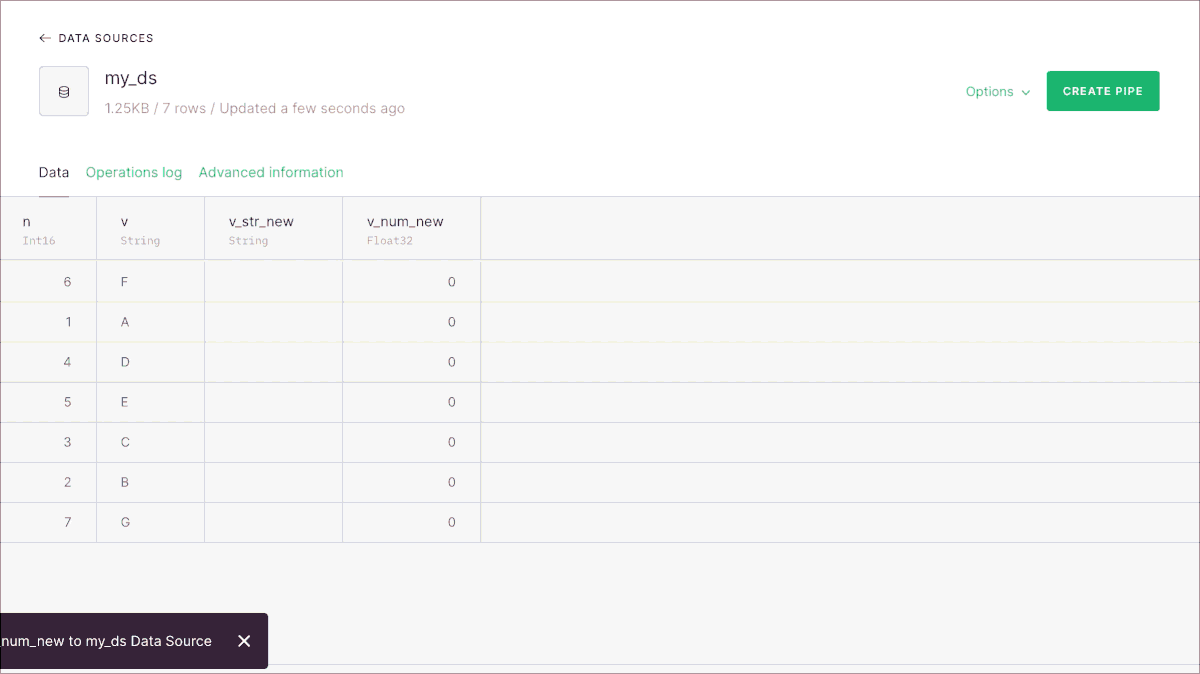
If you’d like to read all the details, read the full annoucement here.
Adding ENGINE_SETTINGS when creating a Data Source
You can also now pass a comma-separated string of keys and values with any of the supported settings for DataSources with a MergeTree-family engine.
CLI and performance improvements
- Now pushing pipes and Data Sources will be much faster in many cases.
- The precedence of the auth token changed: now the value passed with the
--tokenflag has the highest priority, then theTB_TOKENenvironment variable, and then the.tinybfile. - Before, the
drop-prefixwould fail if there were pipes dependant on Data Sources sharing the same prefix; it would try to drop first the Data Sources and that would cause an error because Tinybird would detect that some pipes depended on those. Now, it drops first the pipes and then the Data Sources with a given prefix, so that no errors happen. - There were some cases before when
tb pullwouldn’t return the full schema of the Data Source in the same way that it was created. Now it does, so that you know all the columns present in a Data Source. - Until now, if pushed a pipe or a Data Source with a prefix and you’d try to do it later without prefix, it wouldn’t let you do it. From now on, this won’t happen anymore and you’ll be able to have resources with the same name and different (or no) prefixes in your account.
- See the rest of CLI changes here
UI improvements
- The token management page now shows pipes and Data Sources’ names, instead of IDs.

- Until now, sometimes the autocomplete in our UI wouldn’t detect all the entities available. Now it detects them all, so that working the experience is as good as possible.
- The curl snippet in the UI to create a Data Source from a local CSV file didn’t contain a Data Source name before, and it would fail as that parameter is required when creating it from local file. Now it contains the Data Source name and won’t fail when you try to use it.
Backend improvements
- We’ve been working on a Kafka connector that lets you ingest data in real-time as it arrives to Kafka topics. It’s not open for everyone but it will be soon. If you want to use it already, message us at hi@tinybird.
- Truncating Null Data Sources will not fail anymore.
- Data Source stats are now updated every time a Data Source is replaced or a Materialized View is populated, so that you know at any time how much data is stored in your Data Sources.
- Now data can be appended and replaced in Join Data Sources.