A new authentication provider, a dramatical improvement in Pipes API performance, more reliable APIs thanks to multiple bug fixes and an easter egg! This is what we’ve been working on at Tinybird over the last few weeks.
What’s new?
Sign in with your Microsoft account
We asked our users which are their top three authentication providers for cloud applications and the answers were:
- Microsoft
- And, wait for it… GitHub (of course!, we aim at developers)
We already supported Google’s Authentication and now we have added support Microsoft too. This way you don’t have to deal with a separate account for Tinybird but you can tune your account security by means of MFA, strong passwords or recovery codes through your provider of preference. Github, you are next!
Custom errors in API endpoints
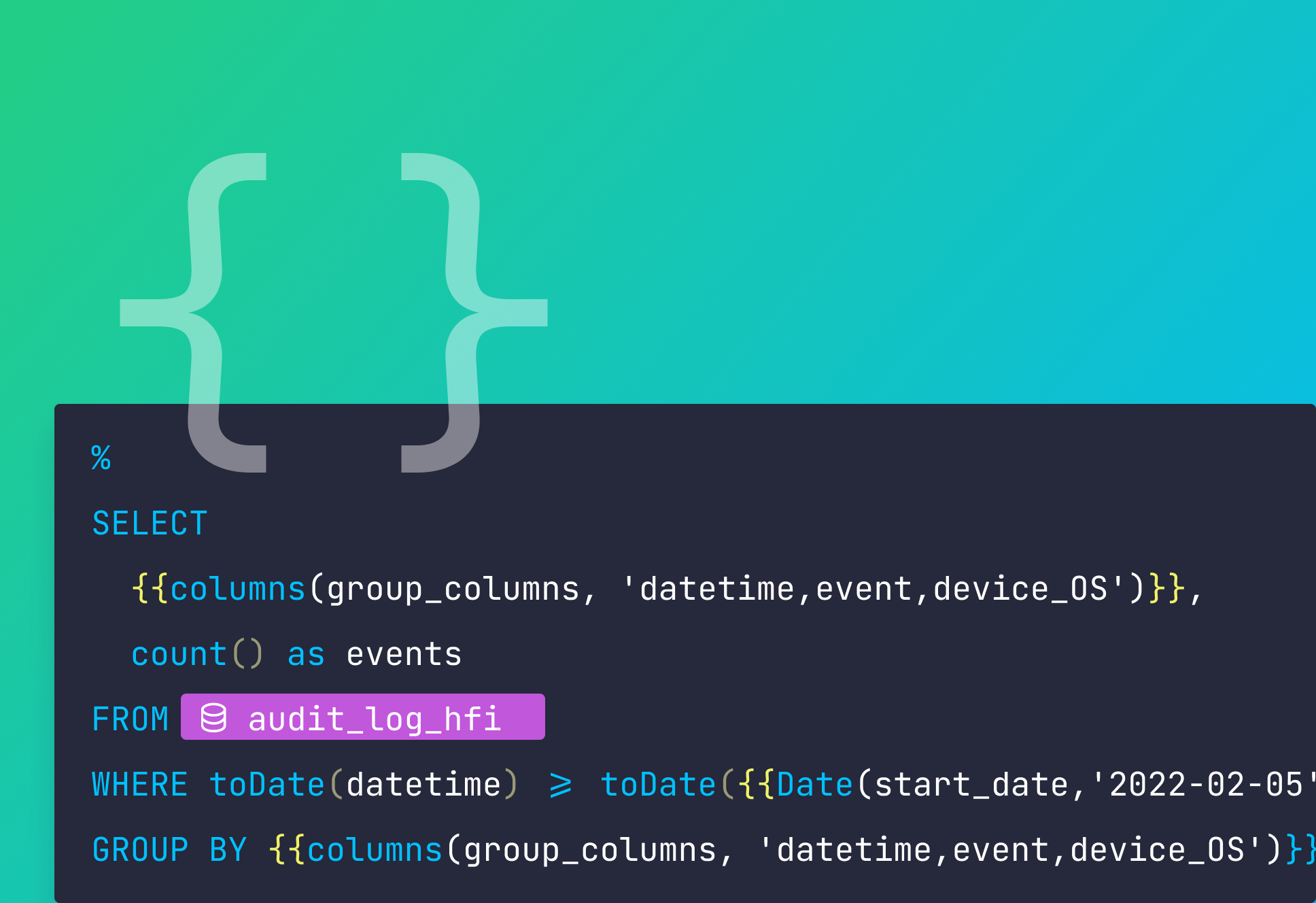
We added a new operator in our SQL templating system to define custom errors in your API endpoints.
This is very handy when you publish an endpoint to be consumed by a third party app and you want to add some validations, such as checking for some required parameters, date ranges or parameter formatting.
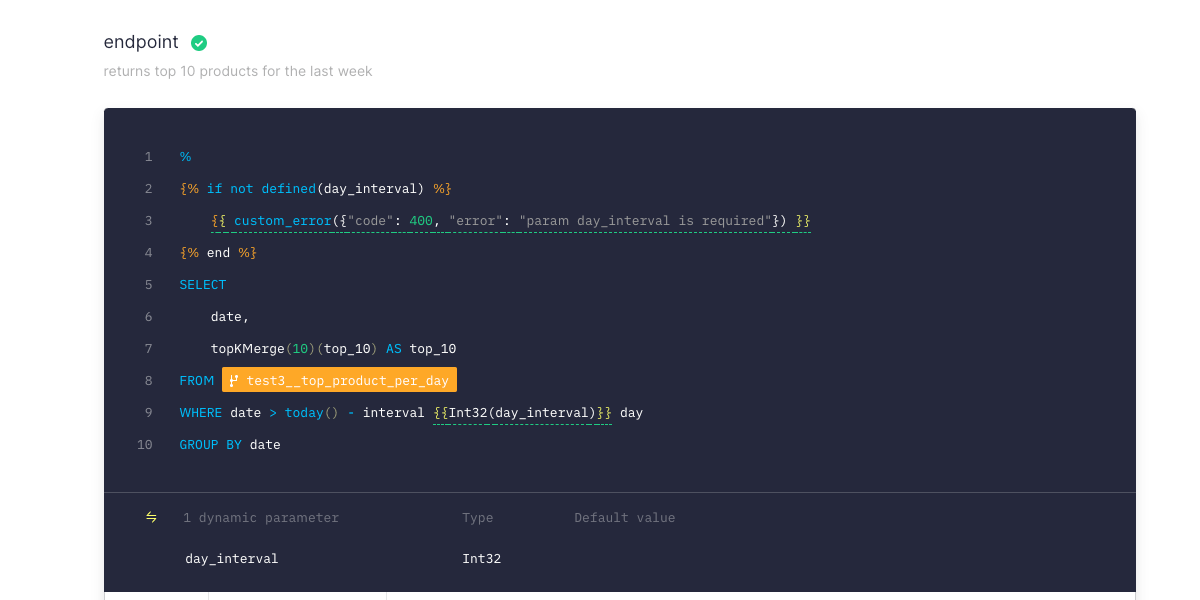
With custom errors you can return error codes and messages any time a validation fails, so the developers integrating the APIs can understand what’s wrong with an invalid API request.

Read more about our API endpoints to get you started right away.
Enhancements
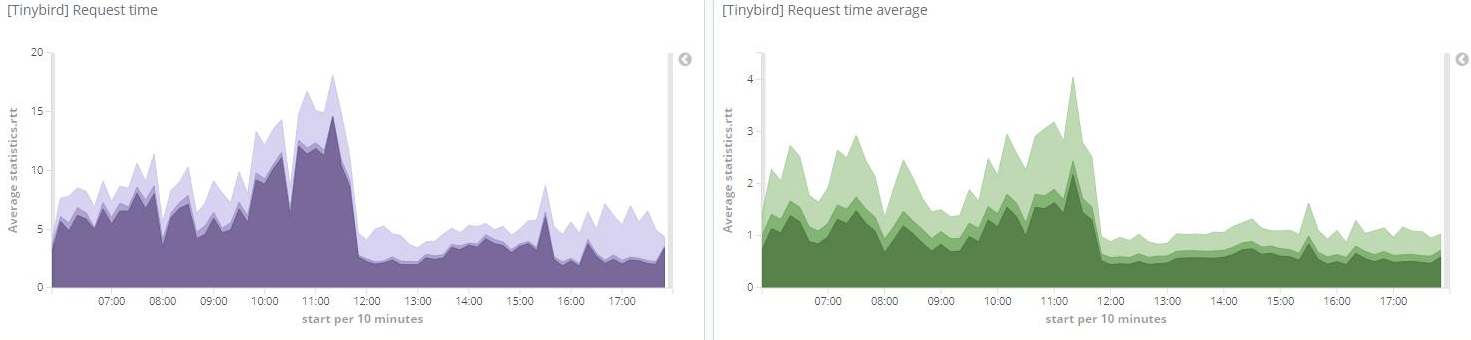
How we made it 7x faster
Speed is, without a doubt, Tinybird’s most important feature.
Recently we detected a way of improving response times of certain API endpoints: those under high concurrency and that rely on Pipes with many nodes and parameters. We did so by analyzing the critical path at the application level, from the parsing of the request to the building of the query, and by getting rid of some extra processing in the SQL templates and by caching some calculations.
We shaved off a few dozen miliseconds per request, but when you are dealing with huge concurrency, these can have a huge impact on the overall performance of real-time analytics APIs.
In fact, up to 7x speed improvement as per one of our real world customer’s metrics, with peaks over 150 rps:
Better syntax highlighting
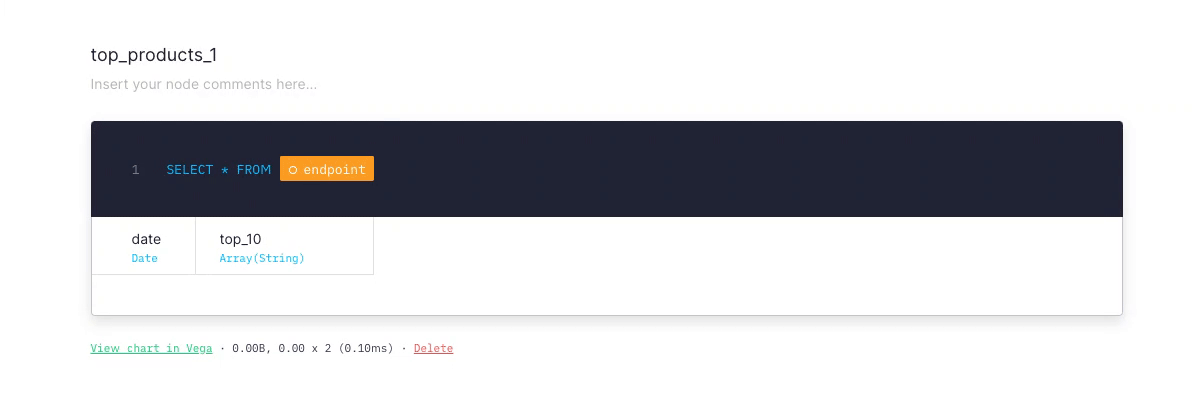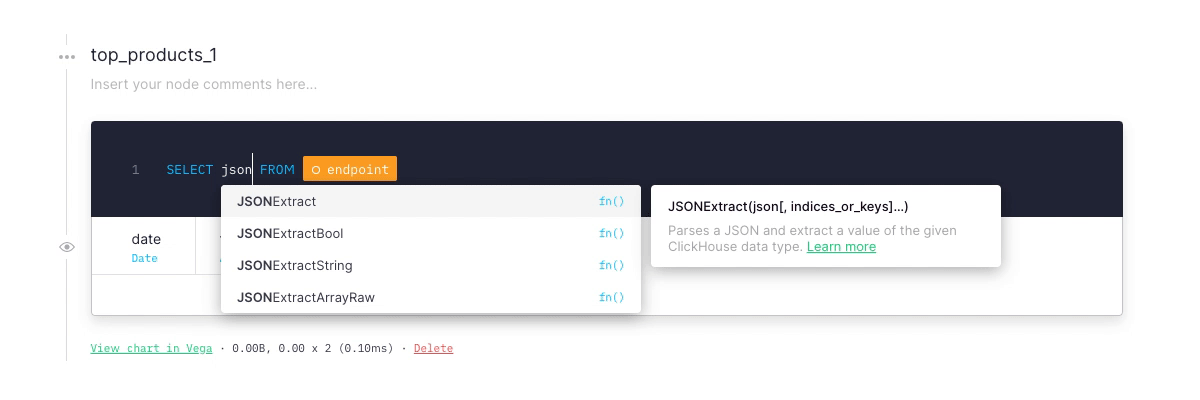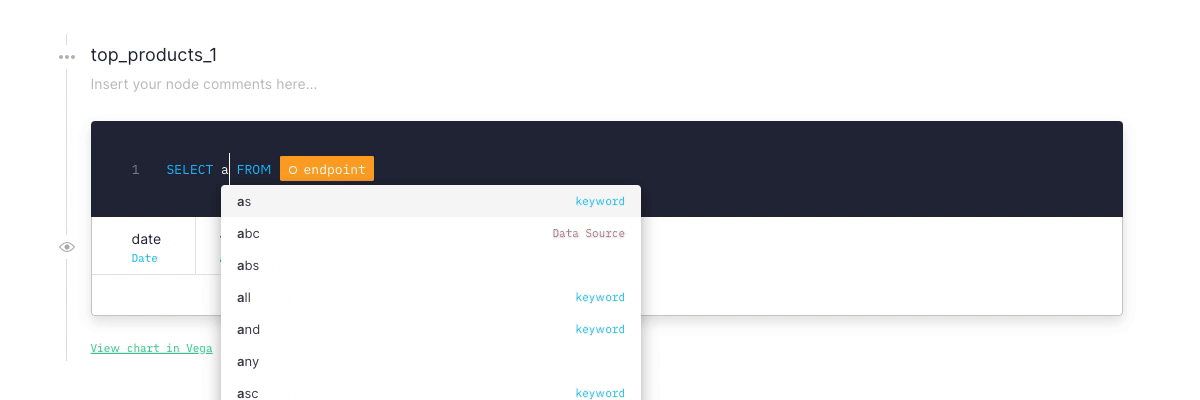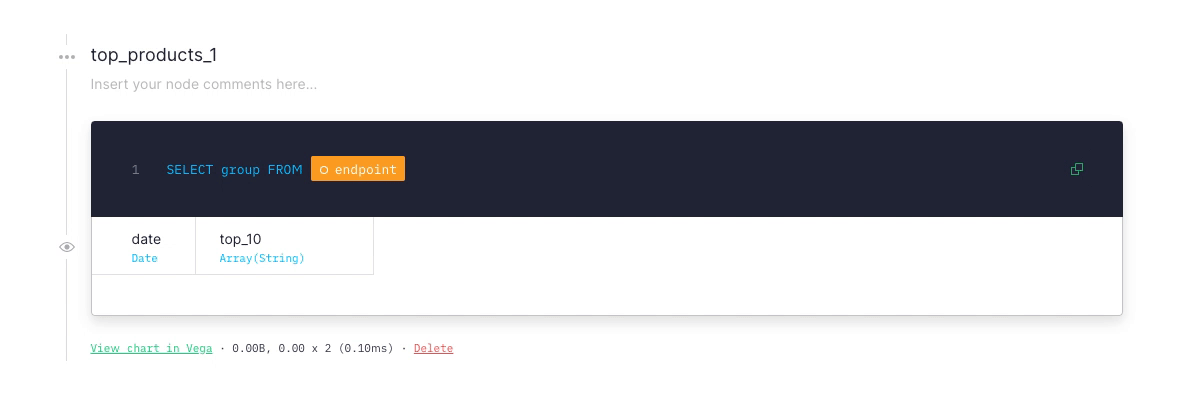
In our previous edition of the CHANGELOG™️ we announced we had deployed the latest stable version of ClickHouse.
It comes with a speed improvement of up to 2x in some of our customers production APIs and a bunch of new built-in operators for dealing with dates, JSON and geospatial functions. We’ve recently added all of those to our SQL highlighting and autocompletion system. Just type, geo, JSON, array or group and autocomplete as you go!
A resizable sidebar
We recently added a “Collapse sidebar” button, handy when you want to focus on writing queries. But have you noticed there’s also a handler to resize the left sidebar?
We also added more space in the jump to functionality (try it by pressing S on the dashboard) for those that use long names for their pipes and data sources.
Bug fixes
We keep working closely with our customers and learning a lot from them. In the process, we’ve tackled a number of bug fixes in our UI and APIs that are having a direct impact on their day to day operations. To name a few:
- Prevent datasource deletion when it’s used in materialized nodes
- Better autocompletion by preserving case sensitivity
- Cleaner token pages
- Several fixes in the public API endpoint page and OpenAPI spec
- Several fixes when (re)populating materialized nodes
Make it more reliable
Probably the bug fix we are most proud of over these last few weeks (and that we could almost consider a new feature) has to do with materialized nodes and how dependent views are populated.
Materialized nodes are one of the most powerful features of our Pipe API: they enable you to transform and enrich data on-the-fly at ingestion time. As always, we want you to be able to append, replace or populate data without worrying about how to keep up-to-date dozens of dependent materialized nodes. We take care of the internals.
Besides that we keep updating our documentation and working in our secret weapon for collaborative data projects. For instance, did you know you can request for your data in multiple formats?
Extra ball 🏎️💨
Have you tried to publish an API endpoint from the UI? We have several easter eggs waiting for you!
We will keep posting this changelog blog posts regularly, but you can also stay up to date with all the changes through our (users only) integrated changelog, which we update with every minor or major change in production.
What are your main challenges when dealing with large quantities of data? Request access to Tinybird and get started with real-time analytics right away.